Node 基础

本文主要记录 Node 基础知识, 包括 Node 的核心模块, Node 的通信等等
一、架构组成
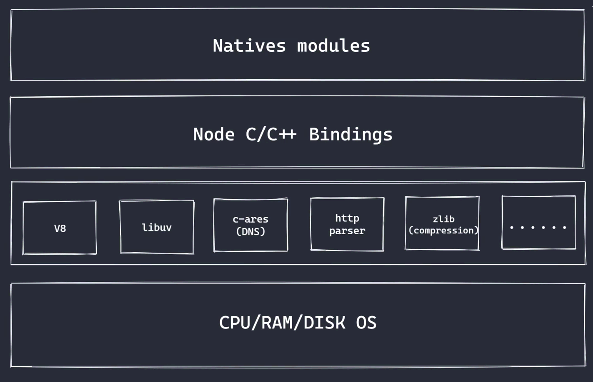
Node 一般分为四层架构:
- Native Modules
- Node C/C++ Bindings
- 底层库
- CPU / RAM / DISK / OS
Native Modules
该层是 Node 内置核心模块, 由 JS 来实现, 包括了fs、path、http等
Node C/C++ Bindings
也叫做Builtin Modules(胶水层), 由 C/C++来完成的一些链接库, 主要链接的是底层具体的 C/C++代码实现, 帮助使用者来调用到底层的库
底层实现
- V8: 执行 JS 代码, 提供桥接接口
- Libuv: 事件循环、时间队列、异步 IO
- 第三方模块: zlib、http、c-areas 等
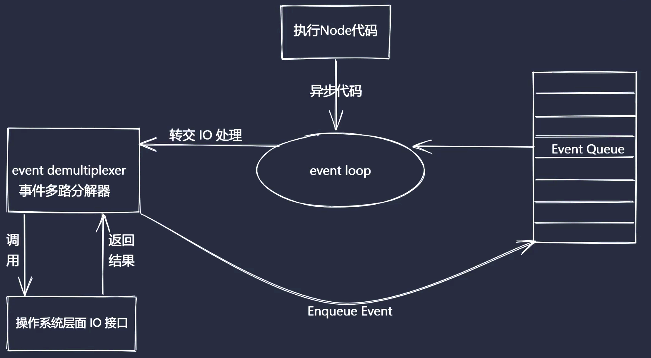
其中, Libuv实现主要是异步 IO 和事件驱动, 架构图大致如下:
CPU / RAM / DISK / OS
最下面一层就是机器码执行以及计算机的运行逻辑
二、全局变量
Process 进程
/* 1.资源查看 */
process.memoryUsage() // cpu
process.cpuUsage() // 内存
/* 2. 运行环境查看 */
process.cwd() // 运行目录
process.version // Node环境版本
process.versions // 查看Node环境的详细版本信息
process.arch // 操作系统架构
process.env // 用户环境多个信息
process.env.NODE_ENV // 获取环境变量
process.env.PATH // 系统环境变量
process.env.USERPROFILE // Win用户目录,如 c:\Users\用户名
process.env.HOME // Mac用户目录, 如/Users/lorain
process.platform // 系统平台(win32 darwin linux)
/* 3. 运行状态 */
process.argv // 命令启动参数
process.argv0 // Node.js 启动时传递process.argv0的原始值的只读副本
process.pid // 该运行的命令占用的进程pid
process.uptime() // 运行时间
/* 4. 事件监听 */
process.on('exit', () => {}) // 监听Node脚本退出事件
process.on('beforeExit', () => {}) // 代码自动退出之前的钩子, 手动调用process.exit() 不触发
/* 4. 标准输入输出 */
process.stdout // 标准输出流
process.stdin // 标准输入流
process.stdin.pipe(process.stdout) // 输入值打印在屏幕上
process.stdin.setEncoding('utf-8')
process.stdin.on('readable', () => {
let chunk = process.stdin.read()
if (chunk !== null) process.stdout.write(`data${chunk}`)
})Buffer 缓冲区
用于实现 Nodejs 平台的二进制数据操作, 不占用 V8 堆内存大小内存空间, 但是内存的使用由 Node 控制, 由 V8 回收。常常配合 Stream 流使用, 充当数据缓冲区。 本文主要记录核心三部分
- Buffer 的创建
- BUffer 实例方法
- BUffer 静态方法
Buffer 的创建
Buffer 是类数组对象, 每位由两个 16 进制数来表示, 占用一个字节空间
Buffer.alloc(size[, fill[, encoding]]) 创建指定字节大小的 buffer
Buffer.allocUnsafe(size) 创建指定大小的 buffer(不安全)
由于空闲空间会被使用, 由于空间碎片存在, 导致使用的内存是不干净的
Buffer.from(array) 创建有初始化数据的 buffer
/* 创建普通缓冲区 */
const bf = Buffer.alloc(10) // 申请10个字节的buffer
console.log(bf) // <Buffer 00 00 00 00 00 00 00 00 00 00>
/* 创建不安全的缓冲区 */
const bf1 = Buffer.allocUnsafe(10)
console.log(bf1) // <Buffer 08 00 00 00 01 00 00 00 00 00>
/* 创建含有初始数据的buffer */
Buffer.from('string', 'utf8')
Buffer.from([0xff, 0b1001, 0o47, 20]) // 可以是16进制, 二进制, 十进制, 八进制, 值范围0-255
Buffer.from(bf) // 通过其他buffer创建新的独立的buffer空间BUffer 实例方法
buffer实例方法, 均需要先创建 buffer 对象, 通过实例调用
- fill(value[, offset[, end]][, encoding]) 使用数据填充 buffer, 前闭后开
- write(string[, offset[, length]][, encoding]) 向 buffer 中写入数据
- toString([encoding[, start[, end]]]) 从 buffer 中提取数据
- subarray([start[, end]]) 截取 buffer
- indexOf(value[, byteOffset][, encoding]) 在 buffer 中查找数据的位置, 未找到返回-1
- copy(target[, targetStart[, sourceStart[, sourceEnd]]]) 拷贝 buffer 中的数据
/* fill使用 */
const buf = Buffer.alloc(5)
buf.fill('1', 1, 3) // 前闭后开区间 <Buffer 00 31 31 00 00>BUffer 静态方法
- Buffer.concat(list[, totalLength]) 合并 buffer, 并返回一个新 Buffer 的
- Buffer.isBuffer(obj) 判断一个对象是否是 buffer
三、核心模块
该部分主要记录最常用的 Node 模块
路径模块-Path
- basename() 路径中的基础名称 (/a/b/c.js->c.js)
- dirname() 路径中的目录名称 (/a/b/c/->c)
- extname() 路径中的扩展名称 (/a/b/c.ts->.ts)
- isAbsolute() 路径是否为绝对路径
- join() 拼接路径片段
- resolve() 返回绝对路径
- parse() 解析路径为一个对象
- format() 序列化路径对象为一个标准路径字串
- normalize() 规范化路径
/* 可以解析相对路径部分 */
path.join('a/b', '../', 'index.js') // 'a/index.js'
path.join('a/b', '/c', 'index.js') // 'a/b/c/index.js'
/* 每部分路径都会解析为有效路径 */
path.resolve('/a/b/c', '../', 'index.ts') // '/a/b/index.ts'
path.resolve('/a/b/c', '/d', 'index.ts') // '/d/index.ts'
/* 规范化为有效路径, 忽略多余的路径符号\/ */
path.normalize('a///b/c../d') // 'a/b/c../d'文件系统-Fs
fs是内置核心模块, 提供文件系统操作的核心 API
权限位、操作符、文件标识符
- 权限位

需要特别注意: 在 win 系统上, 权限一般都是读和写, 即 8 进制表示为 0o666, 十进制为 438
- 文件操作符
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
- 文件标识符 fd
操作系统分配给被打开文件的唯一的标识, 配合打开文件一起使用。
在Node中,0~2 均被占用了, 所以该值由 3 开始递增
文件操作 API
- fs.readFile(path[, options], callback) 从指定文件读取数据
- fs.writeFile(file, data[, options], callback) 向指定文件写入数据
- fs.appendFile(path, data[, options], callback) 追加的方式向指定文件写入数据
- fs.copyFile(src, dest[, mode], callback) 将某个文件中的数据拷贝到另一个文件
- fs.watchFile(filename[, options], listener) 对指定文件进行监控
在Node中, 有很多文件操作都是一次性的操作, 即将内容全部读取到内存中, 然后再进行操作; 这种只适合小文件的操作, 要是文件过大, 就必须通过Buffer来进行切片操作
涉及到大文件的 Api 主要有:
- fs.open(path[, flags[, mode]], callback) 异步打开某文件
- fs.close(fd[, callback]) 通过文件标识符异步关闭已打开某文件
- fs.read(fd, buffer, offset, length, position, callback) 从指定文件中通过 buffer 读取内容片段
- fs.write(fd, buffer, offset[, length[, position]], callback) 向指定文件标识中写入 buffer 片段
目录操作 API
- fs.access(path[, mode], callback) 判断文件或目录是否具有操作权限
- fs.stat(path[, options], callback) 获取目录及文件信息
- fs.mkdir(path[, options], callback) 创建目录
- fs.rmdir(path[, options], callback) 删除目录
- fs.readdir(path[, options], callback) 读取目录中的内容
- fs.unlink(path, callback) 删除指定文件
模块标准-Module
Commonjs是一个同步加载的模块化规范, 主要用于Node, 早期用于弥补 JS 语言模块化的缺陷。在Node中通过两个模块require和module来实现
module 的重要属性
- id 返回模块标识符, 一般是一个绝对路径
- filename 返回文件模块的绝对路径
- loaded 返回布尔值, 表示模块是否完成加载
- parent 返回一个对象, 存放调用当前模块的父模块
- children 返回数组, 存放当前模块调用的其他模块
- exports 返回当前模块需要暴露的内容
- paths 返回数组, 存放不同目录下的
node_modules位置
require 重要属性
- resolve() 返回模块文件绝对路径
- extensions 根据不同后缀名执行解析操作
- main 返回主模块对象
模块加载流程

Resolving:找到待引用的目标模块,并生成绝对路径。
Loading:判断待引用的模块内容是什么类型,依次判断 .js 文件 -> .json 文件 -> .node 文件。
Wrapping:顾名思义,包装被引用的模块。通过包装,让模块具有私有作用域。
Evaluating:被加载的模块被真正的解析和处理执行。
Caching:缓存模块,这让我们在引入相同模块时,不用再重复上述步骤。
Node中模块加载分为四类, 详细机制如下:
I、文件查找
如果被加载的内容为一个路径require('/a'), 判断require加载的路径是绝对路径还是相对路径, 进行路径解析后, 直接查找路径下的a是否存在。如果不存在, 则会在a后面加上.js、.json、.node后缀, 依次查找
II、文件夹查找
当上一步的require('/a')通过添加后缀依旧无法找到时, 则会将该路径下的a作为文件夹来处理。 查找a下的package.json文件, 如果存在, 则解析package.json文件, 查找main字段, 作为目标模块的具体文件名称。如果不存在, 则查找a下的index.js、index.json、index.node文件, 作为目标模块的具体文件名称
III、内置模块查找
如果被加载的内容直接为包名require('path'), 则直接从内置模块中查找, 如果不存在, 则会被认为加载的包是第三方模块
IV、第三方模块查找
当包名不是内置模块, 则会从当前目录下的node_modules文件夹中查找, 并使用文件查找和文件夹查找来处理。 如果不存在, 则会向上一级目录查找, 直到根目录下的node_modules文件夹中查找, 如果还是未找到, 则会报错
沙箱环境-VM
VM是 Node 内置模块,用于创建独立运行的沙箱环境, 支持在 V8 虚拟机上下文中编译和运行代码
核心 API
vm.runInContext(code, contextifiedObject[, options]) 编译 code,在
contextifiedObject的上下文中运行,然后返回结果vm.runInNewContext(code[, contextObject[, options]]) 编译 code,在创建的上下文中运行它,然后返回结果
vm.runInThisContext(code[, options]) 在当前上下文中运行它 global 并返回结果
事件模块-Events
Nodejs是基于事件驱动的异步操作架构, 核心内置了events模块events模块提供了EventEmitter类 , 通过EventEmitter类实现事件统一管理Nodejs中很多内置核心模块继承了EventEmitter, 例如fs、net、http
EventEmitter 常见核心 API
- emitter.on(eventName, listener) 添加当事件被触发时调用的回调函数
- emitter.emit(eventName[, ...args]) 触发事件, 按照注册的序同步调用每个事件监听器
- emitter.once(eventName, listener) 添加当事件在注册之后首次被触发时调用的回调函数
- emitter.off(eventName, listener) 移除特定的监听器
事件循环-EventLoop
Node10 及其之前版本,Microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行 Microtask队列中的任务。
Node版本更新到 11 之后,Event Loop 运行原理发生了变化,一旦执行一个阶段里的一个宏任务Macrotask就立刻执行微任务队列,跟浏览器趋于一致。
任务队列
在Node中分为 6 个任务队列, 其中idle, preare是系统内部占用
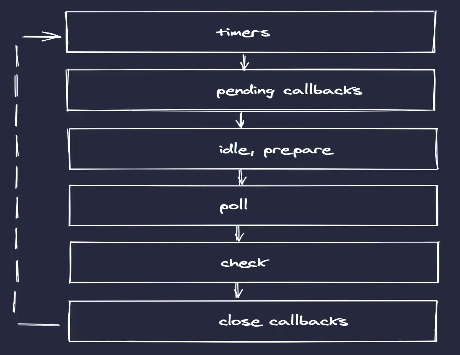
timers: 执行 setTimeout 与 setInterval 回调
pending callbacks: 执行系统操作的回调, 例如 tcp、udp
idle, prepare: 只在系统内部进行使用
poll: 执行与 I/O 相关的回调, 例如 文件 I/O、网络 I/O、信号处理等
check: 执行 setImmediate 中的回调
close callbacks: 执行 close 事件的回调, 例如 socket.on('close', ...)
执行顺序
- 执行同步代码, 将不同的任务添加到相应的队列
- 所有同步代码执行后会去执行满足条件的微任务
- 所有微任务代码执行后会去执行上述6 个任务队列中满足的宏任务
- Node10 及以下: 每个任务队列中宏任务执行完成后, 再去执行该队列中所有的微任务
- Node11 及以上: 每个任务队列中某一个宏任务执行完成后, 就去执行该期间所有的微任务
- 依次切换任务队列执行, 类似于按顺序扫描每个队列
特别需要注意:
Node 版本不同, 微任务执行时机不同, 且微任务
process.nextTick执行顺序优先级大于promise.then()setTimeout和setImmediate执行顺序先后会有一定不稳定(可前可后), 因为setTimeout有个最低延时
// 同步代码->微任务->逐一切换宏任务队列执行
setTimeout(() => {
console.log('s1')
Promise.resolve().then(() => {
console.log('s1->p')
})
process.nextTick(() => {
console.log('s1->tick')
})
})
setTimeout(() => {
console.log('s2')
Promise.resolve().then(() => {
console.log('s2->p')
})
process.nextTick(() => {
console.log('s2->tick')
})
})
Promise.resolve().then(() => {
console.log('p1')
})
console.log('start')
process.nextTick(() => {
console.log('tick')
})
setImmediate(() => {
console.log('sm1')
Promise.resolve().then(() => {
console.log('sm1->p')
})
process.nextTick(() => {
console.log('sm1->tick')
})
})
setImmediate(() => {
console.log('sm2')
Promise.resolve().then(() => {
console.log('sm2->p')
})
process.nextTick(() => {
console.log('sm2->tick')
})
})
console.log('end')
/***** node11+: ****
* 使用命令 npx node@11 xxx.js 执行
start
end
tick
p1
s1
s1->tick
s1->p
s2
s2->tick
s2->p
sm1
sm1->tick
sm1->p
sm2
sm2->tick
sm2->p
*/
/***** node10-: ****
* 使用命令 npx node@10 xxx.js 执行
start
end
tick
p1
s1
s2
s1->tick
s2->tick
s1->p
s2->p
sm1
sm2
sm1->tick
sm2->tick
sm1->p
sm2->p
*/特殊情况
未被任何回调包裹的setTimeout和setImmediate执行顺序是不稳定的, 具有一定的随机性。 因为setTimeout具有一个最低延迟, 所以进入到任务队列的时间存在随机性, 当延迟极低先于setImmediate进入队列, 就会先执行, 否则后执行。
但是将两个代码放入 I/O 操作的回调中, setImmediate永远先于setTimeout执行。因为Node有 6 个任务队列, 每个任务队列执行完后会扫描下一个任务队列, 这个扫描有个先后顺序(上面图示), 依次从上往下扫描; 而 I/O 的回调处于poll队列, 那下一个队列就是check队列, 所以setImmediate先于setTimeout执行
/* 案例一 执行顺序具有随机性 */
setTimeout(() => {
console.log('setTimeout')
})
setImmediate(() => {
console.log('setImmediate')
})
/* 案例二 setImmediate永远先于setTimeout */
require('fs').readFile('xxx', () => {
setTimeout(() => {
console.log('setTimeout')
})
setImmediate(() => {
console.log('setImmediate')
})
})流式编程-Stream
Node 中的流就是处理流式数据的抽象接口, 在文件操作和网络模块均实现了流接口
流处理的优势
- 时间效率 流的分段处理可以同事操作多个数据 chunk
- 空间效率 同一时间流无需占据大的内存空间
- 使用方便 流配合管理,扩展程序变得简单
Node 流的分类
Node内置了stream, 它实现了流操作对象。stream模块实现了四个具体的抽象, 所有流都继承了 EventEmitter 类
- Readable: 可读流, 能够实现数据的读取, 生产供程序消费数据的流
- Writeable: 可写流, 能够实现数据的写操作, 用于消费数据的流
- Duplex: 双工流, 即可读又可写
- Transform: 转换流, 可读可写, 还能实现数据转换
可读流事件
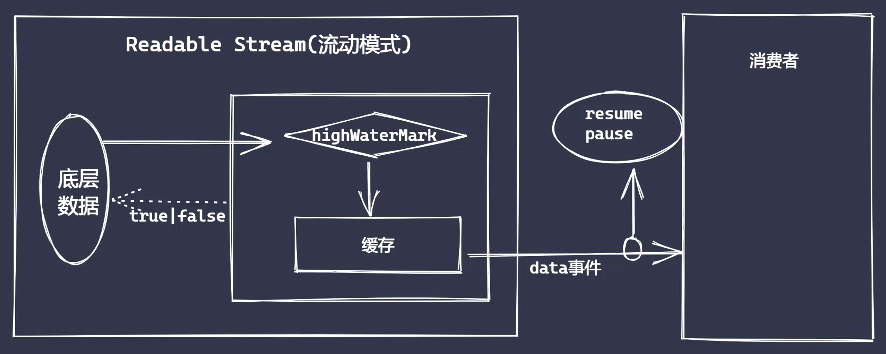
Node为了满足不同数据使用场景,主要分为读取部分数据还是全量数据, 也即流动模式和暂停模式。需要主动调用read()方法(类似于拉)的是暂停模式, 不需要主动调用(类似于推)的是流动模式
- readable 事件: 当流中存在可读取数据时触发, 属于暂停模式
- data 事件: 当流中数据块传给消费者后触发, 属于流动模式
- open 事件: 当可读流被创建(fs.createReadStream)就被触发
- close 事件: 当可读流数据消费完毕, 文件关闭之前触发
- end 事件: 当可读流数据被清空之后触发
- error 事件: 读取发生错误时触发
const fs = require('fs')
const rs = fs.createReadStream('xxx.file')
const bufArray = []
rs.on('data', (chunk) => {
console.log('chunk被读取:', chunk)
// 可以使用数组来存储多个buffer片段
bufArray.push(chunk)
})
// 当createReadStream被调用就会触发open事件
rs.on('open', (fd) => {
console.log('文件被打开了')
})
// 数据被消费完毕之后, 文件将被关闭之前触发
rs.on('close', () => {
console.log('文件被关闭了')
})
// 当数据被消费完成之后触发, 在close事件之前触发
rs.on('end', () => {
console.log('数据已经被处理完成', Buffer.concat(bufArray).toString())
})
rs.on('error', (err) => {
console.log('出错了:', err)
})可读流两种模式转换
可读流包括了流动模式(flowing mode)和暂停模式(paused mode), 两种模式是可以相互转换的, 主要使用readStream.pause()和readStream.resume()来完成
流动模式下,数据会源源不断地生产出来,形成“流动”现象。 监听流的 data 事件便可进入该模式
暂停模式下,需要显示地调用 read(),触发 data 事件
可读流对象 readable 中有一个维护状态的对象,readable._readableState,这里简称为 state。 其中有一个标记,state.flowing, 可用来判别流的模式。 它有三种可能值:
- true 流动模式
- false 暂停模式
- null 初始状态
调用 readable.resume()可使流进入流动模式,state.flowing 被设为 true。 调用 readable.pause()可使流进入暂停模式,state.flowing 被设为 false
const fs = require('fs')
const rs = fs.createReadStream('xxx.file')
// 流动模式->暂停模式
rs.on('data', (chunk) => {
rs.pause()
setTimeout(() => {
rs.resume()
}, 500)
})
// 暂停模式
rs.on('readable', () => {
let data
while ((data = rs.read()) !== null) {
console.log(data.toString())
}
})自定义可读流
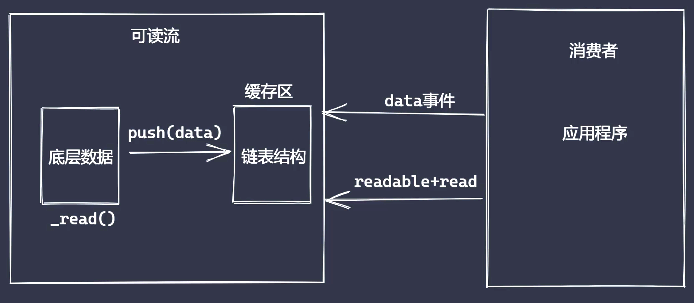
- 继承 stream 里的 Readable 类
- 重写_read 方法调用 push 产生数据
const { Readable } = require('stream')
// 模拟底层数据
const source = ['lorain', 'ivan', 'stream']
// 自定义类继承
class UserReadable extends Readable {
constructor(source) {
super()
this.source = source
}
_read() {
// 数据读完结果为null
const data = this.source.shift() || null
this.push(data)
}
}
const rsInstance = new UserReadable(source)
/* 读取可读流数据方式一: 暂停模式 */
rsInstance.on('readable', () => {
let data = null
while ((data = rsInstance.read()) !== null) {
// 首次会读出2条数据, 因为在该事件触发时, 在数据缓冲区已经有数据了
console.log('data', data.toString())
}
})
/* 读取可读流数据方式二: 流动模式 */
rsInstance.on('data', (chunk) => {
console.log(chunk.toString())
})可写流事件
- pipe 事件: 可读流调用 pipe()方法时触发
- unpipe 事件: 可读流调用 unpipe()方法时触发
- open 事件: 当可读流被创建(fs.createWriteStream)就被触发
- close 事件: 在数据写入操作全部完成, 即调用
writeStream.end()后, 就会触发执行 - error 事件: 语法错误时无法捕获, 只有对文件的操作出错(例如 end 调用后, 又通过 write 写这种错误)才能触发
- drain 事件: 当缓存区可以继续写入数据时触发, 可以用来控制写入速度
- finish 事件: 该'finish'事件在 stream.end()方法被调用后触发,并且所有数据都已刷新到底层系统
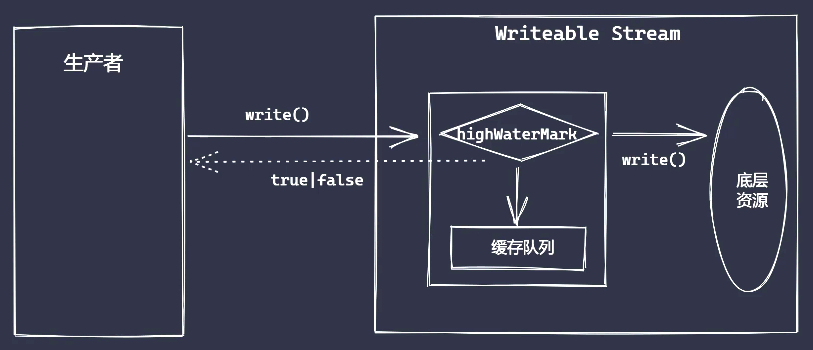
可写流执行流程
可写流缓存区大小默认为 16KB, 第一次调用 write 方法是将数据直接写入文件中, 之后继续调用 write 方法才是将数据写入至缓存区
操作流程中, 由生产者、缓存区和消费者组成。且生产速度要比消费速度快很多
当write操作返回值为 false 之后, 表明消费速度无法跟上生产速度, 我们此时可以将可读流的模块修改为暂停模式
当数据生产者暂停之后, 消费者会慢慢消化内部缓存中的数据, 直到可以再次被执行写入操作
当缓存区可以继续写入数据, 通过drain事件通知生产者
const fs = require('fs')
const ws = fs.createWriteStream('xx.file', { highWaterMark: 3 }) // 水位线为3个字节长度
// 首次直接写入文件, 而不是存入缓存区
let flag = ws.write('1')
// 第二次将存入缓存区, 源码中state.writing被设置为true
flag = ws.write('2')
// 当返回值flag返回为false, 表示累计所写入量已经不小于水位线highWaterMark
// 源码中: state.length < state.highWaterMark, 将触发drain事件
flag = ws.write('3')
// 当flag为false, 即累计所写入量已经不小于水位线highWaterMark, 将触发drain事件
ws.on('drain', () => {})自定义可写流
- 继承 stream 模块的 Writable 类
- 重写_write 方法, 调用 write 执行写入
const { Writable } = require('stream')
class UserWriteable extends Writable {
constructor(source) {
super()
}
_write(chunk, encoding, done) {
process.stdout.write(`${chunk.toString()}----`)
process.nextTick(done)
}
}
const wsWriteable = new UserWriteable()
wsWriteable.write('此处为数据或者可读流', 'utf-8', () => {
console.log('end')
})Duplex & Transform
Duplex 和 Transform 都是两个双工流。 Duplex 流读写相互独立, 它的读操作创建的数据不能直接交由写操作当做数据源使用; 而 Transform 流却是可以的, 即读写是联通的
自定义 Duplex 流, 需要以下步骤:
- 继承 Duplex 类
- 重写_read 方法, 调用 push 生产数据
- 重写_write 方法, 调用 write 消费数据
const { Duplex } = require('stream')
class UserDuplex extends Duplex {
constructor(source) {
super()
this.source = source
}
_read() {
// 数据读完结果为null
const data = this.source.shift() || null
this.push(data)
}
_write(chunk, encoding, next) {
process.stdout.write(chunk)
process.nextTick(next)
}
}
const dpDuplex = new UserDuplex(['1', '2', '3'])
dpDuplex.on('data', (chunk) => {
console.log(chunk.toString())
})
duDuplex.write('数据或者可读流', () => {
console.log('done')
})自定义 Transform, 需要以下步骤:
- 继承 Transform 类
- 重写_transform 方法, 调用 push 和 callback
- (非必须)重写_flush 方法, 处理剩余数据
const { Transform } = require('stream')
class UserTransform extends Transform {
constructor() {
super()
}
_transform(chunk, encoding, cb) {
this.push(chunk.toString().toUpperCase())
cb(null, chunk)
}
}
const t = new UserTransform()
// 可写流写入数据
t.write('a')
// 当成数据读
t.on('data', (chunk) => {
console.log(chunk.toString())
})此处附加一个转换流使用的小案例, 用于将匹配到的.md文件中的内容修改为指定的值
const glob = require('glob')
function getItemByKey(key: string, text: string) {
const matchFiles = `../${key}/*.{md,markdown}`
const path = resolve(__dirname, matchFiles)
const sidebar = { text, collapsed: false, items: [] as any }
const files = glob.sync([path])
for (const file of files) {
const name = basename(file, '.md')
const rs = createReadStream(file, 'utf8')
// 防止出错, 使用一个临时的文件来进行处理
const tmpPath = `${file}.tmp`
const ws = createWriteStream(tmpPath, 'utf8')
// 此处使用转化流对可读流进行转换
const ts = new Transform({
transform(chunk, encoding, callback) {
// 在这里修改文件内容
const mChunk = chunk.toString().replace(/# -/g, `# ${name}`);
callback(null, mChunk);
}
})
rs.pipe(ts).pipe(ws).on('finish', () => {
rename(tmpPath, file, (err) => {
if (err) {
console.error('重命名文件时发生错误:', err);
} else {
console.log('文件修改完成并写回原文件');
}
});
})
sidebar.items.push({
text: name,
link: `/${key}/${name}`
})
}
sidebar.items.sort((a: any, b: any) => {
const noa = a.text.match(/^(\d+)-/)[1]
const nob = b.text.match(/^(\d+)-/)[1]
return noa - nob
})
return [sidebar]
}const fs = require('fs');
const path = require('path');
// 原始文件路径
const originalFilePath = 'a.txt';
// 临时文件路径
const tempFilePath = `${originalFilePath}.tmp`;
// 创建一个读流
const readStream = fs.createReadStream(originalFilePath, { encoding: 'utf8' });
// 创建一个写流
const writeStream = fs.createWriteStream(tempFilePath, { encoding: 'utf8' });
readStream.on('data', (chunk) => {
// 在这里修改文件内容
const modifiedChunk = chunk.toString().replace(/oldText/g, 'newText');
// 将修改后的数据写入到临时文件
writeStream.write(modifiedChunk);
});
readStream.on('end', () => {
// 读取完成后结束写入
writeStream.end();
});
writeStream.on('finish', () => {
// 重命名临时文件为原文件
fs.rename(tempFilePath, originalFilePath, (err) => {
if (err) {
console.error('重命名文件时发生错误:', err);
} else {
console.log('文件修改完成并写回原文件');
}
});
});
readStream.on('error', (err) => {
console.error('读取文件时发生错误:', err);
});
writeStream.on('error', (err) => {
console.error('写入文件时发生错误:', err);
});背压机制
以下代码实现了pipe方法的背压机制
const fs = require('fs')
const rs = fs.createReadStream('源数据.file', { highWaterMark: 4 }) // 可读流水位线, 表示每次读取4个字节
const ws = fs.createWriteStream('目标文件.file', { highWaterMark: 1 }) // 可写流水位线, 表示每次写入1个字节
let flag = true
rs.on('data', (chunk) => {
flag = ws.write(chunk, () => {
console.log('本次已写完')
})
// 当可写流超限, 主动告知生产者暂停
if (!flag) rs.pause()
})
// 文件可写流缓存空间已经可以再次写入了
ws.on('drain', rs.resume)手写可读流实现
const fs = require('fs')
const EventEmitter = require('events')
class CustomReadStream extends EventEmitter {
constructor(
path,
{
flags = 'r',
mode = 0o666, // 八进制:0O666 十进制:438 十六进制:0x1B6
autoClose = true,
start = 0,
end = 0,
encoding = null,
highWaterMark = 64 * 1024 // 默认64KB
}
) {
super()
this.path = path
this.flags = flags
this.mode = mode
this.autoClose = autoClose
this.start = start
this.end = end
this.encoding = encoding
this.highWaterMark = highWaterMark
this.fd = null
this.readOffset = this.start // 写入偏移量
this.open()
// 监听注册的事件,监听data事件时, 开始读取数据
this.on('newListener', (type) => {
if (type === 'data') this.read()
})
}
close() {
fs.close(this.fd, () => {
this.emit('close')
})
}
read() {
const buf = Buffer.alloc(this.highWaterMark)
if (typeof this.fd !== 'number') {
return this.once('open', this.read)
}
const needReadLens = this.end
? Math.min(this.end - this.readOffset + 1, this.highWaterMark)
: this.highWaterMark
fs.read(
this.fd,
buf,
0,
needReadLens,
this.readOffset,
(err, readBytes) => {
if (readBytes) {
this.readOffset += readBytes
this.emit('data', buf.slice(0, readBytes))
this.read()
} else {
this.emit('end')
this.close()
}
}
)
}
open() {
fs.open(this.path, this.flags, (err, fd) => {
if (err) return this.emit('error', err)
this.fd = fd
this.emit('open', fd)
})
}
}
let rs = new CustomReadStream('test.txt', { highWaterMark: 3, end: 7 }) // end可以读到, 总共8个值
rs.on('data', (chunk) => {
console.log(chunk)
})
rs.on('close', () => {
console.log('文件已关闭')
})手写可写流实现
const fs = require('fs')
const EventEmitter = require('events')
const Queue = require('./queue')
class CustomWriteStream extends EventEmitter {
constructor(
path,
{
flags = 'w',
mode = 0o666,
autoClose = true,
start = 0,
encoding = 'utf8',
highWaterMark = 16 * 1024
}
) {
super()
this.path = path
this.flags = flags
this.mode = mode
this.autoClose = autoClose
this.start = start
this.encoding = encoding
this.highWaterMark = highWaterMark
this.fd = null
this.writeOffset = this.start // 写入偏移量
this.writing = false
this.writeLen = 0
this.needDrain = false
this.cache = new Queue()
this.open()
}
open() {
console.log('open')
fs.open(this.path, this.flags, (err, fd) => {
if (err) return this.emit('error', err)
this.fd = fd
this.emit('open', fd)
})
}
// 真正的写操作函数
_write(chunk, encoding, cb) {
// 写入操作放入异步, 导致fd是undefined
if (typeof this.fd !== 'number') {
return this.once('open', () => this._write(chunk, encoding, cb))
}
fs.write(
this.fd,
chunk,
this.start,
chunk.length,
this.writeOffset,
(err, writtenBytes) => {
this.writeOffset += writtenBytes // 偏移量移动
this.writeLen -= writtenBytes
cb && cb()
}
)
}
_clearBuffer() {
let data = this.cache.deQueue()
if (data) {
this._write(data.element.chunk, data.element.encoding, () => {
data.element.cb && data.element.cb()
this._clearBuffer()
})
} else {
if (this.needDrain) {
this.needDrain = false
this.emit('drain')
}
}
}
write(chunk, encoding, cb) {
chunk = Buffer.isBuffer(chunk) ? chunk : Buffer.from(chunk)
// 调用多次write会积压writeLen, 生产速度远大于消费速度
this.writeLen += chunk.length
let flag = this.writeLen < this.highWaterMark
this.needDrain = !flag
if (this.writing) {
// 当前正在执行写入, 所以内容应该排队
this.cache.enQueue({ chunk, encoding, cb })
} else {
this.writing = true
// 当前不是正在写入, 那么执行写入
this._write(chunk, encoding, () => {
cb()
// 清空排队缓存区
this._clearBuffer()
})
}
return flag
}
}
const ws = new CustomWriteStream('./test.txt', { highWaterMark: 3 })
ws.on('open', (fd) => {
console.log(fd)
})
let flag = ws.write('1', 'utf8', () => {
console.log('ok1')
})
console.log(flag)
flag = ws.write('10', 'utf8', () => {
console.log('ok2')
})
flag = ws.write('ssss', 'utf8', () => {
console.log('ok2')
})
flag = ws.write('11111', 'utf8', () => {
console.log('ok2')
})
ws.on('error', (e) => {
console.log('---', e)
})四、网络通信
通信必要条件:
- 主机之间需要有传输介质
- 主机必须有网卡设备
- 主机之间需要协商网络速率
网络模型
OSI 七层网络模型
应用层: 用户与网络的接口, 包括 FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS
表示层: 数据加密、转换、压缩, 包括 JPEG、MPEG、ASII
会话层: 控制网咯连接建立与终止, 包括 NFS、SQL、NETBIOS、RPC
传输层: 控制数据传输可靠性, 包括 TCP、UDP、SPX
网络层: 确定目标网络, 包括 IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP、 (路由器)
数据链路层: 确定目标主机, 包括 PPP、FR、HDLC、VLAN、MAC (网桥,交换机)
物理层: 各种物理设备和标准, 包括 RJ45、CLOCK、IEEE802.3 (中继器,集线器)
TCP / IP 四层网路模型
- 应用层: 对应会话层 + 表示层 + 应用层
- 传输层: 同 OSI 七层模型
- 主机层: 对应网络层
- 接入层: 对应数据链路 + 物理层
数据如果从 A 主机传输到 B 主机, 首先是按照分层自上而下的顺序, 进行数据封装。到 B 主机网卡解调过后, 再按照自下向上的顺序进行数据拆解, 最后在应用层拿到 A 发来的原始数据
TCP 协议
TCP是一个处于传输层, 基于端口, 面向连接的协议,且主机之间通信前需要先建立双向数据通道。TCP 的捂手和挥手本质上都是四次,握手阶段将 ACK 和 SYN 合并在一起,而挥手阶段不能合并该数据, 由于一个服务端服务需要服务多台客户端, 因此增加一条数据来确认断开谁的连接
常见控制字段主要是SYN,FIN,ACK
- SYN = 1 表示请求建立连接
- FIN = 1 表示请求断开连接
- ACK = 1 表示数据信息确认
TCP 三次握手
- 客户端首次发送
SYN = 1的申请连接信号给服务端 - 服务端收到信号后, 回复
ACK = 1(收到连接请求) ,SYN = 1(同意建立连接)的信号给客户端 - 客户端收到这条信息后, 发送
ACK = 1到服务端, 表示已经确认收到信息, 同时建立连接
TCP 四次挥手
- 第一次挥手: 发起方向被动方发送报文,FIN、ACK、SEQ,表示已经没有数据传输了, 并进入 FIN_WAIT_1 状态
- 第二次挥手: 被动方发送报文,ACK、SEQ,表示同意关闭请求, 此时主机发起方进入 FIN_WAIT_2 状态
- 第三次挥手: 被动方向发起方发送报文段,FIN、ACK、SEQ,请求关闭连接, 并进入 LAST_ACK 状态
- 第四次挥手: 发起方向被动方发送报文段,ACK、SEQ, 然后进入等待 TIME_WAIT 状态, 被动方收到发起方的报文段以后关闭连接。发起方等待一定时间未收到回复,则正常关闭
创建 TCP
在Node中使用Net模块可以创建基于流操作的 TCP 通信, Net模块通信主要事件或者方法包括:
- listening 事件: 调用
server.listen方法后触发 - connection 事件: 新的连接建立时触发
- close 事件: 当 server 关闭时触发
- error 事件: 当错误出现时触发
Net实例的时间或者方法:
- data 事件: 当接收到数据时触发
- write 方法: 在
socket上发送数据, 默认是UTF8编码 - end 事件 & end 方法: 当
socket的一端发送 FIN 包时触发, 结束可读端
通信样例代码:
TCP 粘包
通信包含数据发送端和接收端, 发送端累计数据统一进行发送, 而接收端也会进行缓冲数据之后再消费, 这种设计可以减少 IO 操作带来的性能消耗, 但是也会带来粘包问题
要解决粘包问题, 可以在每次发送的数据之间增加一点延迟, 而最佳的实现方式是通过对数据包进行封包和解包
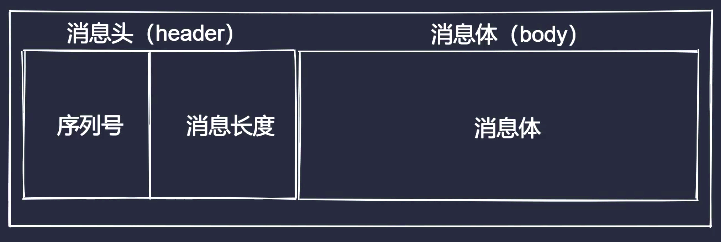
数据封包拆包
消息主要由消息头(header)和消息体(body)两部分构成, 其中序列号+消息长度组成消息头
数据传输过程:
- 进行数据编码, 获取二进制数据包
- 按规则拆解数据, 获取指定长度的数据
数据读写一般由 Buffer 来完成:
- buf.writeInt16BE(value[, offset]): 将 value 从指定位置写入
- buf.readInt16BE([offset]): 从指定位置开始读取数据
class CustomDataTransform {
constructor() {
// header总长度
this.packageHeaderLen = 4
// 序列号
this.serialNo = 0
// 序列号长度
this.serialNoLen = 2
}
// 编码
encode(data, serialNo) {
const body = Buffer.from(data)
// 先按照指定长度申请内存作为header
const headerBuf = Buffer.alloc(this.packageHeaderLen)
// 消息头->序列号部分, 固定长度
headerBuf.writeInt16BE(serialNo || this.serialNo)
// 消息头->消息体长度部分, 非固定长度
headerBuf.writeInt16BE(body.length, this.serialNoLen)
if (serialNo === undefined) this.serialNo++
return Buffer.concat([headerBuf, body])
}
// 解码
decode(buffer) {
const headerBuf = buffer.slice(0, this.packageHeaderLen)
const bodyBuf = buffer.slice(this.packageHeaderLen)
return {
//读2个字节
serialNo: headerBuf.readInt16BE(), // 序列号
bodyLen: headerBuf.readInt16BE(this.serialNoLen), // 消息体长度
body: bodyBuf.toString() // 消息体
}
}
// 获取数据包长度
getPackageLen(buffer) {
if (buffer.length < this.packageHeaderLen) return 0 // 包不完整或者数据还未传输完毕
// buffer.readInt16BE(this.serialNoLen)刚好读出消息体长度
// 上面headerBuf.writeInt16BE(body.length, this.serialNoLen)是匹配的
return this.packageHeaderLen + buffer.readInt16BE(this.serialNoLen)
}
}
// 测试代码
/* const trans = new CustomDataTransform()
const str = '这是一段测试文本'
const enRes = trans.encode(str, 1)
console.log('编码后的数据包', enRes)
const deRes = trans.decode(enRes)
console.log('解码后的数据包', deRes)
const lens = trans.getPackageLen(enRes)
console.log('数据包长度', lens) */通过利用上面封装的封包解包库, 可以更好的解决粘包问题, 示例代码如下
HTTP 协议
HTTP是建立在TCP之上的超文本传输协议, 它处于 OSI 模型的应用层。 使用net库来建立一个服务, 通过浏览器发起请求过后, 可以看到收到的请求整体是一个类似字符串的文本
请求消息结构
请求由四部分组成, 分别是请求行、请求头、请求空行、请求体
- 请求行:分别是 请求方法 + 空格 + URL + 空格 + 协议版本 + \r\n.
- 请求头部:由多个请求头部 键值对 组成,中间以冒号 : 隔开,每个 键值对 最后是 \r\n.
- 空行:即 \r\n.
- 请求包体:包体部分
GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10*10_5)
Accept: */\_响应消息结构
- 状态行:分别是协议版本+空格+状态码+空格+状态码描述+\r\n
- 响应头部:由多个响应头部键值对组成,中间以冒号:隔开,每个键值对最后是\r\n
- 空行:即\r\n
- 响应包体:包体部分
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 82
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello HTTP</body>
</html>其余不多赘述, 此处记录几篇相关文章
中间代理服务器 & 静态服务器
Node常用场景可以充当代理服务器及静态服务器, 也可以用于来解决客户端跨域、BFF 等, 以下是一些使用场景的示例代码
HTTP 静态服务命令行工具
