MongoDB基础

NoSQL(Not Only SQL), 也叫做非关系型数据库, 与之相对应的是RDB(关系型数据库)。 非关系型数据库是把数据直接放进一个大仓库、不标号、不连线、单纯的堆起来,从而提高了对海量数据的高性能存储及访问,而本篇所介绍的MongoDB就是该类型数据库的一种
一、认识 NoSQL
分类
如今市面上的 NoSQL 数据库主要分为以下几类
键值数据库
在存储时不采用任何模式,因此极易添加数据,且具备极高的读写性能,适用处理大量数据的高访问负载,例如日志系统。主要代表便是
Redis、Flare文档型数据库
满足海量数据存储和访问的需求, 同时对字段要求不严格, 可以随意增加、删除、修改字段,且不需要预先定义表结构,使用网络应用。主要代表是
MongoDB、CouchDB列存储型数据库
查找速度快,可扩展性强,适合用作分布式文件存储系统。主要代表是
Cassandra、Hbase图数据库
利用“图结构”的相关算法来存储实体之间的关系信息,适用于构建社交网络和推荐系统的关系图谱。主要代表是
InfoGrid、Neo4
选型
- NoSQL 适用模型关系性比较低的应用, 不太适合多表关联的场景
- 对数据量多且访问速度要求高的场景
- 对数据的一致性要求不高的场景, 事务处理和一致性方面属于 NoSQL 的缺点
- 数据可用性高的场景
征对多种业务场景, 项目中可以选用多种数据库, 将其拆开设计, 将需要 RDB 特性的放到 RDB 中管理, 而其他数据放到 NoSQL 中管理
二、MongoDB 使用场景
需要高性能处理大量的低价值数据: 对低价值数据存取性能有较高要求, 数据不需太高的事务性
需要借助缓存层来处理数据: 作为持久化缓存层, 避免底层存储的资源过载
需要高度的伸缩性的场景: 当关系型数据库由于量级导致性能急剧下降时, 可以作为补充搭建集群环境, 实现最大程度扩展
三、安装及配置
官方的下载及安装地址,请点击MongoDB Community Server DownloadMongoDB
安装方式主要有两种:
- 手动安装
- 使用Homebrew安装
手动安装
以下示例以Macos为例, Unix和Linux 均能通用
# 下载最新(2024/05/17)安装包
curl -LO https://fastdl.mongodb.org/osx/mongodb-macos-x86_64-7.0.9.tgz
# 解压缩
tar -zxvf mongodb-macos-x86_64-7.0.9.tgz
# 移动到指定目录
mv mongodb-macos-x86_64-7.0.9 /usr/local/mongodb
# 添加环境变量并重载配置
echo 'export PATH=/usr/local/mongodb/bin:$PATH' >> ~/.bash_profile
source ~/.bash_profile
# 创建数据库存放目录以及设定权限
cd /usr/local/var
mkdir mongodb db
chmod -R 777 db
# 创建日志存放文件夹以及设定权限
mkdir -p /usr/local/var/log/mongodb
# 通过命令运行数据库
# --dbpath 指定数据库存放路径
# --logpath 指定日志存放路径
# --config 指定配置文件
# --fork 后台运行
mongod --dbpath="/usr/local/var/mongodb"
# 检查是否启动成功
ps aux | grep mongod自动安装
以下还是以Macos为例, 首先保证系统中安装了Homebrew, 然后使用Homebrew来完成安装
# 下载homebrew的formula
brew tap mongodb/brew
# 下载
brew install mongodb-community@7.0
# 运行
brew services start mongodb-community@7.0
# 停止
brew services stop mongodb-community@7.0配置文件
每次启动mongodb都需要指定数据库存放路径, 日志存放路径等, 为了方便管理, 可以创建配置文件, 通过配置文件来指定这些参数
- 使用参数
# 确认配置是否成功
mongod --version
# 启动和停止MongoDB数据库服务
mongod --dbpath="/usr/local/var/mongodb"- 使用配置文件(推荐)
# 创建配置文件
sudo touch /usr/local/etc/mongod.conf
# 编辑配置文件
sudo vim /usr/local/etc/mongod.conf
# 后续启动时指定配置文件
mongod --config /usr/local/etc/mongod.conf我们将本机的配置修改为如下内容, 如需配置更多选项请参考官方的Options Mapping
systemLog:
destination: file
path: /usr/local/var/log/mongodb/mongo.log
logAppend: true
storage:
dbPath: /usr/local/var/mongodb
processManagement:
fork: true注意
mongod命令开启后, 默认占用本地端口27017
GUI工具
- Robo 3T: 一个开源的 MongoDB 管理工具, 支持 Windows、Mac、Linux 等多个平台
- Navicat: 强大的数据库管理工具,需付费使用。它支持多种数据库系统, 并支持多平台
- MongoDB Compass: 官方的 MongoDB 管理工具, 支持 Windows、Mac、Linux 等多个平台
四、Mongo Shell
以下记录一些基本的操作, 官方的文档请点击MongoDB Manual
连接MongoDB服务
- 通过端口连接本地MongoDB服务
# 连接默认端口的本地服务
mongosh
# 连接非默认端口的本地服务
mongosh --port 28017- 连接远程主机上的MongoDB服务
# 直接通过url参数连接
mongosh "mongodb://mongodb.example.com:28015"
# 通过主机shell参数 --host --port连接诶
mongosh --host mongodb.example.com --port 28015
# 携带身份认证信息(url参数)
mongosh "mongodb://alice@mongodb.example.com:28015/?authSource=admin"
# 携带身份认证信息(shell参数), 不填入密码, 在输入命令后会弹出输入密码的交互
mongosh --username admin --password ----authenticationDatabase admin --host 127.0.0.1 --port 28015注意
mongod和mongosh的区别:
- mongod: 开启MongoDB数据库服务
- mongosh: 连接MongoDB的服务
Mongo Shell执行环境
- 提供JavaScript执行环境
- 内置一些数据库操作命令(例如
show dbs、db、use database、show collection) - 提供了一大堆的内置API来操作数据库(
db.users.insert({ name: 'Jack', age: 18 }))
五、基础概念
由于MongoDB是文档型数据库, 其中存储的数据就是熟悉的JSON格式数据
- MongoDB数据库可以想象为超级大对象
- 对象里面有不同的集合
- 集合中有不同的文档
{
// 数据库 Database
"京东": {
// 集合 Collection, 对应关系数据库中的Table
"用户": [
// 文档 Document, 对应关系数据库中的Row
{
// 数据字段Field, 对应关系数据库中的Column
id: 1,
username: "张三",
passowrd: "123"
},
{
id: 2,
username: "李四",
passowrd: "345"
}
]
}
}数据库
在MongoDB中, 数据库包含一个或者多个文档集合
MongoDB默认的数据库为test, 如果你没有创建新的数据库, 集合将存放在test数据库中
INFO
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
admin: 从权限的角度来看,这是“root”数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
查看数据库
# 查看数据库列表
show dbs
# 显示当前数据库
db切换数据库
use <DATABASE_NAME>开发者可以切换到不存在的数据库(数据库中真正有了数据才会被创建出来)。首次将数据存储在数据库中(例如通过创建集合)时,MongoDB会创建数据库。
例如,以下代码在 insertone()操作期间创建数据库myNewDatabase和集合 myCollection:
# 切换到myNewDataBase数据库
use myNewDataBase
# 插入一条数据
db.myCollection.insertOne({ x: 1 })命名规则
数据库名称规则
- 不区分大小写,但是建议全部小写
- 不能包含空字符
- 数据库名称不能为空,并且必须少于64个字符
- Windows 上的命名限制
不能包括
/\. "$*<>:|?中的任何内容
- Unix 和 Linux 上的命名限制
不能包括
/\. "$中的任何字符
如需了解更多命名方面的规则, 可以查看官网命名规则文档
删除数据库
# 删除当前数据库
db.dropDatabase()集合
集合类似于关系数据库中的表, 存储多个对象, MongoDB将文档存储在集合中

创建集合
MongoDB提供 db.createCollection()方法来显式创建具有各种选项的集合,例如设置最大大小或文档验证规则。如果未指定这些选项,则无需显式创建集合,因为在首次存储集合数据时, MongoDB会创建新集合。
// <COLLECTION_NAME>为集合名
db.<COLLECTION_NAME>.insert({ name: 'John' })命名规则
集合名称应以下划线或字母字符开头,并且包含以下约束
- 不能包含
$ - 不能为空字符串
- 不能包含空字符
- 不能以
.开头 - 长度限制
- 版本 4.2 最大
120个字节- 版本 4.4 最大
255个字节
- 版本 4.4 最大
查看集合
show collections删除集合
// <COLLECTION_NAME>为指定集合名
db.<COLLECTION_NAME>.drop()文档
文档 Document, 对应关系数据库中的Row。文档结构由字段和值对应组成, 类似于如下结构:
{
field1: 'John',
field2: 25,
field3: 'A',
field4: ['news', 'sports']
}- MongoDB 将数据记录存储为
BSON文档
字段名称
文档对字段名称有以下限制:
- 字段名称
_id保留用作主键;它的值在集合中必须是唯一的,不可变的,并且可以是数组以外的任何类型(一般不指定)。 - 字段名称不能包含空字符。
- 顶级字段名称不能以美元符号$开头。
从MongoDB 3.6 开始,服务器允许存储包含点.和美元符号 $ 的字段名称
数据类型
字段的值可以是任何 BSON 数据类型,包括其他文档,数组和文档数组。
例如,以下文档包含各种类型的值:
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ], 7
views : NumberLong(1250000)
}上面的字段具有以下数据类型:
_id保存一个Objectld类型name包含一个嵌入式文档,该文档包含first和last字段birth和death持有Date类型的值contribs保存一个字符串数组views拥有NumberLong类型的值
MongoDB支持的常用数据类型, 请查看官网BSON类型列表
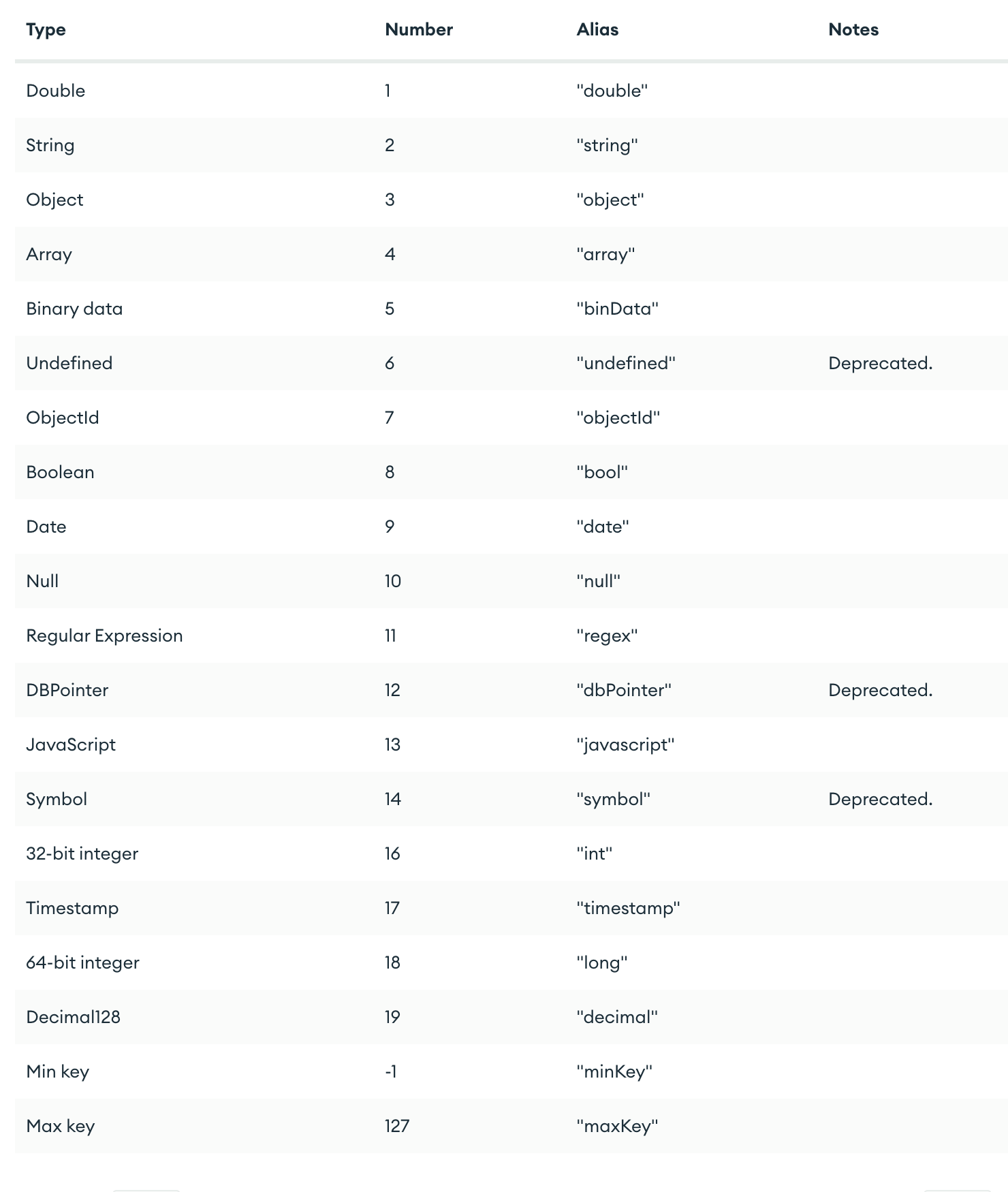
六、创建文档
创建或插入操作将新文档添加到集合中。如果集合当前不存在,则插入操作将创建集合。 MongoDB 提供以下方法,用于将文档插入集合中:
| 操作 | 用途 | 备注 |
|---|---|---|
| db.collection.insertOne() | 插入单个文档到集合中 | 推荐, 插入结果会返回ID |
| db.collection.insertMany() | 插入多个文档到集合中 | 推荐, 插入结果会返回ID |
| db.collection.insert() | 将1个或多个文档插入到集合中, 参数与前两个一样 | 不推荐, 结果仅返回插入数 |
插入单个文档
db.inventory.insertOne(
{
item: "canvas",
qty: 100,
tags: ["cotton"],
size: { h: 28, w: 35.5, uom: "cm" }
}
)插入多个文档
db.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], size: { h: 14, w: 21, uom: "cm"}},
{ item: "mat", qty: 85, tags: ["gray"], size: { h: 27.9, w: 35.5, uom: "cm" }},
{ item: "mousepad", qty: 25, tags: ["gel", "blue"], size: { h: 19, w: 22.85, uom: "cm"}}
])插入行为
集合创建: 如果该集合当前不存在,则插入操作将创建该集合
_id字段: 在MongoDB中,存储在集合中的每个文档都需要一个唯一的_id字段作为主键。如果插入的文档省略_id字段,则MongoDB驱动程序会自动为_id字段生成Objectld
七、查询文档
读取操作从集合中检索文档;即查询集合中的文档。
基本查询
MongoDB提供了以下方法来从集合中读取文档:
db.collection.find(query, projection)
query: 可选,使用查询操作符指定查询条件projection: 可选,使用投影操作符指定返回的键。查询时返回文档中所有键值,只需省略该参数即可(默认省略)。
db.users.find(
{ age: { $gt: 18 } },
{ name: 1, address: 1}
).limit(5)db.collection.findOne()
首先生成一堆测试数据, 用来做查询测试
db.inventory.insertMany([
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);查询所有文档
db.inventory.find({})
// 格式化打印结果
db.inventory.find({}).pretty()该操作对应于关系数据库中以下语句:
SELECT * FROM inventory查询返回文档指定字段
// 查询结果中包含item和qty字段, 1为包含字段, 0为排除字段
db.inventory.find({}, { item: 1, qty: 1 })
// 查询结果中排除status和qty字段
db.inventory.find({}, { status: 0, qty: 0 })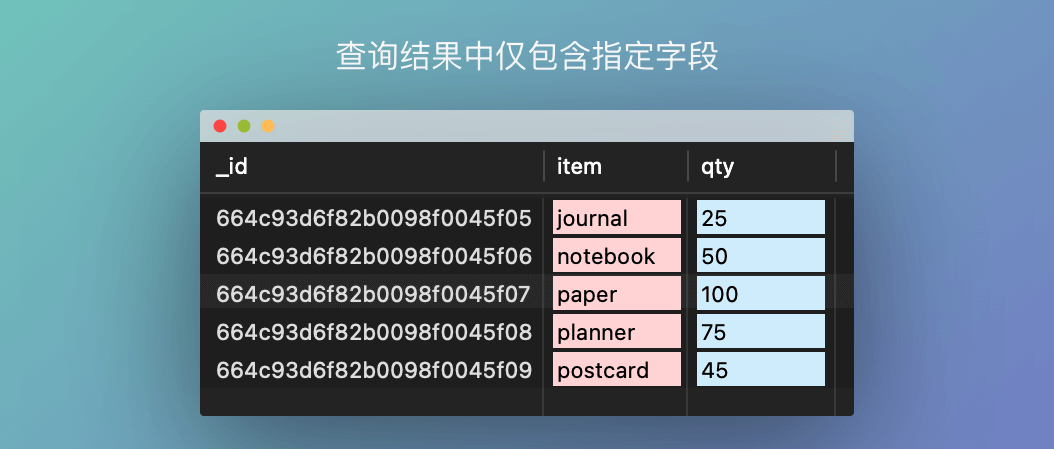
相等条件查询
相等条件查询也就是精确匹配
db.inventory.find( { status: "D" } )该操作对应于以下SQL语句:
SELECT * FROM inventory WHERE status = “D” 语句指定 AND 条件
指定AND条件, 也就是查询参数中通过多个字段来查询, 每个字段都有独立的查询条件, 最终所有的字段条件必须全部满足(还可以使用$and方式)
// 指定多个字段, 省略了$and
// 以下示例检索状态为“A”且数量小于(`$lt`) 30的清单集合中的所有文档:
db.inventory.find({
status: "A",
qty: { $lt: 30 }
})该操作对应于以下SQL语句:
SELECT * FROM inventory WHERE status = "A" AND qty < 30指定 OR 条件
使用 $or 运算符,您可以指定一个复合查询,该查询将每个子句与一个逻辑或连接相连接,以便该查询选择集合中至少匹配一个条件的文档。 下面的示例检索状态为A或数量小于 $lt30 的集合中的所有文档
db.inventory.find({
$or: [
{ status: "A" },
{ qty: { $lt: 30 }}
]
})该操作对应于以下 SQL 语句:
SELECT * FROM inventory WHERE status = "A" OR qty < 30查询运算符
概念
查询运算符是一些特殊的关键字, 用于确定查询的匹配条件。
查询运算符大致分为如下两类
- 查询和投影操作符
- 更新操作符
使用查询运算符指定条件
下面的示例从状态为 “A” 或 “D” 等于 “库存”的清单集中检索所有文档:
db.inventory.find( { status: { $in: [ "A", "D" ] }})该操作对应以下 SQL 语句:
SELECT * FROM inventory WHERE status in ("A", "D")查询操作符又分为:
- 比较查询操作符
- 逻辑查询操作符
- 元素查询操作符
- 评估查询操作符
- 地理空间查询操作符
- 数组查询操作符
- 按位查询操作符
- 投影操作符
- 其他查询操作符
更多查询操作符的内容, 请查看官网查询运算符
查询嵌套文档
查询嵌套文档, 是指通过嵌套文档的下层字段来查询文档
以下是一份原始嵌套文档数据,size下层的一些数据就属于嵌套文档
// 1
{
"_id": ObjectId("664c93d6f82b0098f0045f05"),
"item": "journal",
"qty": 25,
"size": {
"h": 14,
"w": 21,
"uom": "cm"
},
"status": "A"
}
// 2
{
"_id": ObjectId("664c93d6f82b0098f0045f06"),
"item": "notebook",
"qty": 50,
"size": {
"h": 8.5,
"w": 11,
"uom": "in"
},
"status": "A"
}
// 3
{
"_id": ObjectId("664c93d6f82b0098f0045f07"),
"item": "paper",
"qty": 100,
"size": {
"h": 8.5,
"w": 11,
"uom": "in"
},
"status": "D"
}匹配嵌套文档
要在嵌入或嵌套文档的字段上指定相等条件,请使用查询过滤器文档 {<field>:<value>},其中<value>是要匹配的文档。
例如,以下查询选择字段大小等于文档{h: 14, w: 21, uom: "cm"}的所有文档:
// 单字段的精确匹配
db.inventory.find({
size: { h: 14, w: 21, uom: "cm" }
})整个嵌入式文档上的相等匹配要求与指定的<value>文档完全匹配,包括字段顺序
例如,以下查询与库存收集中的任何文档都不匹配:
db.inventory.find({
// w 和 h 与数据库的文档顺序不一样, 将不会匹配到
size: { w: 21, h: 14, uom: "cm" }
})查询嵌套字段
要在嵌入式/嵌套文档中的字段上指定查询条件,请使用点符号("field.nestedField")。
注意
使用点符号查询时,字段和嵌套字段必须在引号内。
1. 在嵌套字段上指定相等匹配
以下示例选择嵌套在 size 字段中的 uom 字段等于 cm 的所有文档:
db.inventory.find({
"size.uom": "cm"
})2.使用查询运算符指定匹配项
查询过滤器文档可以使用查询运算符以以下形式指定条件:
{ <field1>: { <operator1>: <value1> }, …. }以下查询在 size 字段中嵌入的字段 h 上使用小于运算符 $lt
db.inventory.find({
"size.h": { $lt: 15 }
})3. 指定AND条件
以下查询选择嵌套字段h小于15,且嵌套字段uom等于"in", 且状态字段等于"D"的所有文档:
// 通过多个字段联合查询, 必须满足所有字段的所有条件
db.inventory.find({
"size.h": { $lt: 15 },
"size.uom": "in",
status: "D"
})查询数组
首先准备一些测试数据, 用于下面的查询测试
db.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], dim_cm: [ 14, 21 ] },
{ item: "notebook", qty: 50, tags: ["red", "blank"], dim_cm: [ 14, 21 ] },
{ item: "paper", qty: 100, tags: ["red", "blank", "plain"], dim_cm: [ 14, 21 ] },
{ item: "planner", qty: 75, tags: ["blank", "red"], dim_cm: [ 22.85, 30 ] },
{ item: "postcard", qty: 45, tags: ["blue"], dim_cm: [ 10, 15.25 ] }
]);匹配一个数组
要在数组上指定相等条件,请使用查询文档{<field>: <value>},其中<value>是要匹配的精确数组,包括元素的顺序
下面的示例查询所有文档,其中字段标签值是按指定顺序恰好具有两个元素"red"和 "blank"的数组
// 单字段tags数组的整体精确匹配
db.inventory.find({
tags: ["red", "blank"]
})相反,如果您希望找到一个同时包含元素"red"和"blank"的数组,而不考虑顺序或该数组中的其他元素,请使用$all运算符
// 文档中必须包含这两个于元素, 可以顺序不同, 还可以有其他元素
db.inventory.find({
tags: { $all: ["red", "blank"] }
})查询数组中的元素
要查询数组字段是否包含至少一个具有指定值的元素,请使用过滤器 {<field>: <value>},其中 <value> 是元素值。
以下示例查询所有文档,其中tags 是一个包含字符串"red"作为其元素之一的数组
// 单字段模糊匹配
// 只要文档中tags数组中包含"red"的都能被查询到
db.inventory.find({
tags: "red"
})要在数组字段中的元素上指定条件查询,请在查询过滤器文档中使用查询运算符
{ <array field>: { <operator1>: <value1>, ... } }例如,以下操作查询数组 dim_cm包含至少一个值大于25的元素的所有文档
db.inventory.find({
dim_cm: { $gt: 25 }
})为数组元素指定多个条件
在数组元素上指定复合条件时,可以指定查询,以使单个数组元素满足这些条件,或者数组元素的任何组合均满足条件
1. 使用数组元素上的复合过滤条件查询数组
以下示例查询文档,其中 dim_cm 数组包含以某种组合满足查询条件的元素
例如,一个元素可以满足大于 15 的条件,或者另一个元素可以满足小于 20 的条件; 或者单个元素可以满足以下两个条件
// 包含大于15的元素, 或者包含小于20的元素, 或者包含满足两者(15<x<20)之间的元素
db.inventory.find( { dim_cm: { $gt: 15, $lt: 20 } } )征对单字段的多个条件之间满足一条就匹配上, 条件之间是或关系, 例如上例
如果
find传递多个字段联合查询($and), 需要满足多个字段的多个条件
2. 查询满足多个条件的数组元素
使用$elemMatch运算符可以在数组的元素上指定多个条件,以使至少一个数组元素满足所有指定的条件
以下示例查询在 dim_cm 数组中包含至少一个同时 大于22 和 小于30 的元素的文档
db.inventory.find({
// 同时满足 22<x<30
dim_cm: { $elemMatch: { $gt: 22, $lt: 30 } }
})3.通过数组索引位置查询元素
使用点符号,可以为数组的特定索引或位置指定元素的查询条件。该数组使用基于零的索引
注意:使用点符号查询时,字段和嵌套字段必须在引号内
下面的示例查询数组dim_cm中第二个元素大于25的所有文档
db.inventory.find( { "dim_cm.1": { $gt: 25 } } )4. 通过数组长度查询数组
使用 $size 运算符可按元素数量查询数组
例如,以下选择数组标签具有3个元素的文档
db.inventory.find( { "tags": { $size: 3 } })查询嵌入文档的数组
首先准备好测试数据, 用于后面的查询测试
// 数组中嵌套文档
db.inventory.insertMany([
{ item: "notebook", instock: [{ warehouse: "C", qty: 5 }] },
{ item: "paper", instock: [{ warehouse: "A", qty: 60 }, { warehouse: "B", qty: 15 }] },
{ item: "planner", instock: [{ warehouse: "A", qty: 40 }, { warehouse: "B", qty: 5 }] },
{ item: "journal", instock: [{ warehouse: "A", qty: 5 }, { warehouse: "C", qty: 15 }] },
{ item: "postcard", instock: [{ warehouse: "B", qty: 15 }, { warehouse: "C", qty:35 }] }
])查询嵌套在数组中的文档
以下示例选择库存数组中的元素与指定文档匹配的所有文档:
// 单字段instock下数组元素{ warehouse: "A", qty: 5 }的精确匹配
db.inventory.find({
instock: { warehouse: "A", qty: 5 }
})整个嵌入式/嵌套文档上的相等匹配要求与指定文档(包括字段顺序)完全匹配。
例如,以下查询与库存收集中的任何文档都不匹配
db.inventory.find({
instock: { qty: 5, warehouse: "A" }
})查询嵌套数组文档通过查询条件
1. 在嵌入文档数组中的字段上指定查询条件
如果您不知道嵌套在数组中的文档的索引位置,请使用点(.)和嵌套文档中的字段名称来连接数组字段的名称。
下面的示例选择所有库存数组中包含至少一个嵌入式文档的嵌入式文档,这些嵌入式文档包含值小于或等于20的字段qty
db.inventory.find( { 'instock.qty': { $lte: 20 } } )2. 使用数组索引在嵌入式文档中查询字段
使用点表示法,您可以为文档中特定索引或数组位置处的字段指定查询条件。该数组使用基于零的索引
注意
使用点符号查询时,字段和索引必须在引号内。
下面的示例选择所有库存文件,其中库存数组的第一个元素是包含值小于或等于20的字段qty的文档
db.inventory.find( { 'instock.0.qty': { $lte: 20 } })为文档数组指定多个条件
在嵌套在文档数组中的多个字段上指定条件时,可以指定查询,以使单个文档满足这些条件,或者数组中文档的任何组合(包括单个文档)都满足条件。
1. 单个嵌套文档在嵌套字段上满足多个查询条件
使用$elemMatch运算符可在一组嵌入式文档上指定多个条件,以使至少一个嵌入式文档满足所有指定条件
下面的示例查询库存数组中至少有一个嵌入式文档的文档,这些文档同时包含等于5的字段qty和等于A的字段warehouse
// $elemMatch的条件表示同时满足(类似于与)
db.inventory.find( { "instock": { $elemMatch: { qty: 5, warehouse: "A" } } } )如下例查询库存数组中至少有一个嵌入式文档的嵌入式文档包含的字段qty大于10且小于等于20
// 10 < x < 20
db.inventory.find( { "instock": { $elemMatch: { qty: { $gt: 10, $lte: 20 } } } } )2. 元素组合满足标准
如果数组字段上的复合查询条件未使用$elemMatch运算符, 则查询将选择其数组包含满足条件的元素的任意组合的那些文档。
例如,以下查询匹配文档,其中嵌套在库存数组中的任何文档的qty字段都大于10,而数组中的任何文档(但不一定是同一嵌入式文档)的qty字段小于或等于20
// 满足任一条件$gt或者$lte都能查询到(类似于或)
db.inventory.find( { "instock.qty": { $gt: 10, $lte: 20 } } )下面的示例查询库存数组中具有至少一个包含数量等于5的嵌入式文档和至少一个包含等于A的字段仓库的嵌入式文档(但不一定是同一嵌入式文档)的文档:
// 两个条件可以是不同的文档, 但需两个同时满足(即不同的数组元素), instock数组中有两个文档对象, 分别满足这两个条件即可
// { instock: [{ qty: 5 }, { warehouse: 'A' }] }
db.inventory.find( { "instock.qty": 5, "instock.warehouse": "A" } )指定返回的项目字段
默认情况下,MongoDB 中的查询返回匹配文档中的所有字段。要限制 MongoDB 发送给应用程序的数据量,可以包含一个投影文档以指定或限制要返回的字段。
db.inventory.insertMany([
{ item: "journal", status: "A", size: { h: 14, w: 21, uom: "cm" }, instock: [{ warehouse: "A", qty: 60 }]},
{ item: "notebook", status: "A", size: { h: 8.5, w:11, uom: "in" }, instock: [{ warehouse: "A", qty: 40 }]},
{ item: "paper", status: "D", size: { h: 8.5, w: 11, uom: "in" }, instock: [{ warehouse: "A", qty: 5 }]},
{ item: "planner", status: "D", size: { h: 22.85, w: 30, uom: "cm" }, instock: [{ warehouse: "B", qty: 15 }]},
{ item: "postcard", status: "A", size: {h: 10, w: 15.25, uom: "cm" }, instock: [{ warehouse: "C", qty: 15 }]}
]);返回匹配文档中所有字段
下面的示例返回状态为 “A” 的清单集合中所有文档的所有字段
db.inventory.find( { status: "A" } )仅返回指定字段和 _id 字段
通过将投影文档中的 <field> 设置为 1,投影可以显式包含多个字段。以下操作返回与查询匹配的所有文档。在结果集中,在匹配的文档中仅返回项目,状态和默认情况下的 _id 字段
db.inventory.find( { status: "A" }, { item: 1, status: 1 } )禁止 _id 字段
您可以通过将投影中的_id字段设置为0来从结果中删除_id字段,如以下示例所示:
db.inventory.find( { status: "A" }, { item: 1, status: 1, _id: 0 } )返回所有但排除的字段
您可以使用投影排除特定字段,而不用列出要在匹配文档中返回的字段。以下示例返回匹配文档中状态和库存字段以外的所有字段:
db.inventory.find({ status: "A" }, { status: 0, instock: 0 })返回嵌入式文档中的特定字段
开发者可以返回嵌入式文档中的特定字段。使用点表示法引用嵌入式字段,并在投影文档中将其设置为1
以下示例返回:
- _id 字段(默认情况下返回)item 字段
- status 字段
- size 文档中的 uom 字段
- uom 字段仍嵌入在尺寸文档中。
db.inventory.find(
{ status: "A" },
{ item: 1, status: 1, "size.uom": 1 }
)从MongoDB 4.4 开始,您还可以使用嵌套形式指定嵌入式字段,例如fitem: 1, status: 1,size: { uom: 1 }。
禁止嵌入文档中的特定字段
您可以隐藏嵌入式文档中的特定字段。使用点表示法引用投影文档中的嵌入字段并将其设置为0
以下示例指定一个投影,以排除尺寸文档内的uom字段。其他所有字段均在匹配的文档中返回
db.inventory.find(
{ status: "A" },
{ "size.uom": 0 }
)从 MongoDB 4.4 开始,您还可以使用嵌套形式指定嵌入式字段,例如{size: {uom:0 }}
在数组中的嵌入式文档上投射
使用点表示法可将特定字段投影在嵌入数组的文档中。以下示例指定要返回的投影:
_id字段(默认情况下返回)item字段status字段qty数组中嵌入的文档中的instock字段
db.inventory.find( { status: "A" }, { item: 1, status: 1, "instock.qty": 1 } )返回数组中的项目特定数组元素
对于包含数组的字段,MongoDB 提供以下用于操纵数组的投影运算符:$elemMatch,$slice 和$。 下面的示例使用 $slice 投影运算符返回库存数组中的最后一个元素:
$slice规则
- 如果
$slice值为正数, 表示返回前 n 个元素 - 如果
$slice值为负数, 表示返回后 n 个元素 - 如果
$slice值大于数组元素数量, 则返回所有数组元素
db.inventory.find(
{ status: "A" },
{ item: 1, status: 1, instock: { $slice: -1 } }
)$elemMatch、 $slice和$是投影要包含在返回数组中的特定元素的唯一方法。例如,您不能使用数组索引来投影特定的数组元素。例如(“instock.0": 1)投影不会投影第一个元素的数组。
查询空字段或缺少字段
MongoDB 中的不同查询运算符对空值的处理方式不同。 首先准备测试数据如下
db.inventory.insertMany([
{_id: 1, item: null },
{ _id: 2 }
])相等过滤器
{ item: null } 查询将匹配包含其值为 null 的 item 字段或不包含 item 字段的文档。
下面示例查询返回集合中的两个文档
db.inventory.find({ item: null })类型检查
{ item: { $type: 10 } }查询仅匹配包含 item 字段,其值为 null 的文档;即 item 字段的值为 BSON 类型为 Null (类型编号10)
下面示例查询仅返回 item 字段值为 null的文档
db.inventory.find({ item : { $type: 10 } })存在检查
{ item: { $exists: false } }查询结果返回不包含item字段的文档匹配
下面示例查询仅返回不包含项目字段的文档
db.inventory.find({ item : { $exists: false } })八、更新文档
更新操作会修改集合中的现有文档。MongoDB提供了以下方法来更新集合的文档
更新的三种方式
db.collection.updateOne(<filter>, <update>, <options>)db.collection.updateMany(<filter>, <update>, <options>)db.collection.replaceone(<filter>, <update>, <options>)
您可以指定标识要更新的文档的条件或过滤器。这些过滤器使用与读取操作相同的语法。
db.users.updateMany( // <----- collection
{ age: { $lt: 18 } }, // <----- update filter
{ $set: { status: "reject" } } // <----- update action
)现在我们来准备好测试数据, 进行下文的更新测试
db.inventory.insertMany([
{ item: "canvas", qty: 100, size: { h: 28, w: 35.5, uom: "cm" }, status: "A" },
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "mat", qty: 85, size: { h: 27.9, w: 35.5, uom: "cm" }, status: "A" },
{ item: "mousepad", qty: 25, size: { h: 19, w: 22.85, uom: "cm" }, status: "P" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "P" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" },
{ item: "sketchbook", qty: 80, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "sketch pad", qty: 95, size: { h: 22.85, w: 30.5, uom: "cm" }, status: "A"}
])语法
为了更新文档, MongoDB提供了更新操作符(例如$set)来修改字段值。 要使用更新运算符,请将以下形式的更新文档传递给更新方法:
{
<update operator>: { <field1>: <value1>, ... },
<update operator>: { <field2>: <value2>, ... }
}如果该字段不存在,则某些更新运算符( 例如$set、$currentDate) 将创建该字段。有关详细信息,请参见各个更新操作员参考。
更新单个文档
下面的示例在清单集合上使用db.collection.updateone()方法更新项目等于paper的第一个文档
更新操作
- 使用
$set运算符将size.uom字段的值更新为cm,将状态字段的值更新为P - 使用
$currentDate运算符将lastModified字段的值更新为当前日期。如果lastModified字段不存在,则$currentDate将创建该字段
db.inventory.updateOne(
{ item: "paper" },
{
$set: { "size.uom": "cm", status: "P" },
$currentDate: { lastModified: true }
}
)更新多个文档
以下示例在清单集合上使用db.collection.updateMany() 方法来更新数量小于50的所有文档
多个更新操作
- 使用
$set运算符将size.uom字段的值更新为"in",将状态字段的值更新为"p" - 使用
$currentDate运算符将lastModified字段的值更新为当前日期。如果lastModified字段不存在,则$currentDate将创建该字段。
db.inventory.updateMany(
// 会把匹配到的文档全部更新, 如果需要更新所有文档, 就指定当前条件为{}
{ "qty": { $lt: 50 } },
{
$set: { "size.uom": "in", status: "P" },
$currentDate: { lastModified: true }
}
)替换文档
要替换_id 字段以外的文档的全部内容,请将一个全新的文档作为第二个参数传递给db.collection.replaceOne()
替换文档时,替换文档必须仅由字段 - 值对组成, 即不包含更新运算符表达式
替换文档可以具有与原始文档不同的字段。在替换文档中,由于 _id 字段是不可变的,因此可以省略_id 字段;但是,如果您确实包含_id 字段,则它必须与当前值具有相同的值
以下示例替换了清单集合中项目“paper”的第一个文档
db.inventory.replaceOne(
{ item: "paper" },
{ item: "paper", instock: [{ warehouse: "A", qty: 60 }, { warehouse: "B", qty: 40 }] }
)九、删除文档
删除操作从集合中删除文档。MongoDB提供了以下删除集合文档的方法:
删除的几种方式
db.collection.deleteMany()db.collection.deleteOne()
您可以指定标准或过滤器,以标识要删除的文档。这些过滤器使用与读取操作相同的语法。
db.users.deleteMany( // <---------- collection
{ status: "reject" } // <---------- delete filter
)准备如下测试数据, 进行后续的删除文档操作
db.inventory.insertMany( [
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "P" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" }
]);删除所有文档
要删除集合中的所有文档, 请将空的过滤器文档{}传递给db.collection.deleteMany()方法
以下示例从清单收集中删除所有文档
db.inventory.deleteMany({})该方法返回具有操作状态的文档。有关更多信息和示例,请参见deleteMany()
删除所有符合条件的文档
您可以指定标准或过滤器,以标识要删除的文档。筛选器使用与读取操作相同的语法。
- 要指定相等条件,请在查询过滤器文档中使用
<field>: <value>表达式
{ <field1>: <value1>, ... }- 查询过滤器文档可以使用查询运算符以以下形式指定条件
{ <field1>: { <operator1>: <value1> }, … }要删除所有符合删除条件的文档,请将过滤器参数传递给deleteMany()方法。
该方法返回具有操作状态的文档。有关更多信息和示例,请参考deleteMany()
以下示例从状态字段等于“A”的清单集合中删除所有文档
db.inventory.deleteMany({ status : "A" })仅删除单个符合条件的文档
要删除最多一个与指定过滤器匹配的文档(即使多个文档可能与指定过滤器匹配),
请使用db.collection.deleteOne()方法。下面的示例删除状态为“D”的第一个文档
db.inventory.deleteOne({ status: "D" })十、如何在Node环境使用
为了更好的吸收这些知识点,接下来的章节便是学以致用,通过实战案例来体会数据库是如何与Web服务结合起来进行使用的。内容主要分为以下几个部分:
- 在
NodeJS中操作MongoDB MongoDB数据库与Web服务结合实战
在Node中操作MongoDB
首先附录官方两个操作文档, 如果想更深入的了解请点击查看
初始化示例项目
mkdir node-mongodb-demo
cd node-mongodb-demo
pnpm init
pnpm add mongodb连接到MongoDB
import { MongoClient } from "mongodb"
// Connection URI
const uri = "mongodb://localhost:27017";
// Create a new MongoClient
const client = new MongoClient(uri);
async function run() {
try {
// Connect the client to the server 10
await client.connect();
// Establish and verify connection
const db = client.db("hello");
const inventoryCollection = db.collection('inventory')
const res = await inventoryCollection.find().toArray()
console.log("Connected successfully to server", res);
} catch {
console.log('Connect failed')
} finally {
// Ensures that the client will close when you finish/error 18
// 关闭数据库连接
await client.close();
}
}
run()CRUD 操作
CRUD (创建,读取,更新,删除)操作使您可以处理存储在MongoDB中的数据。
创建文档
- 插入一个
const pizzaDocument = {
name: "Neapolitan pizza",
shape: "round",
toppings: [ "San Marzano tomatoes", "mozzarella di bufala cheese" ],
};
const result = await pizzaCollection.insertOne(pizzaDocument);
console.dir(result.insertedId);- 插入多个
const pizzaDocuments = [
{ name: "Sicilian pizza", shape: "square" }, 3
{ name: "New York pizza", shape: "round" },
{ name: "Grandma pizza", shape: "square" },
];
const result = pizzaCollection.insertMany(pizzaDocuments);
// 插入多个返回结果有数量属性: insertedCount
console.dir(result.insertedCount, result.insertedIds);查询文档
const findResult = await orders.find({
name: "Lemony Snicket",
date: {
$gte: new Date(new Date().setHours(00, 00, 00)),
$lt: new Date(new Date().setHours(23, 59, 59)),
}
});删除文档
import { ObjectId } from 'mongodb'
// ...省略中间代码
// 删除符合条件的单个文档
const ret = { _id: new ObjectId('6656db02ad94f607a50a192e') }
const deleteResult = await collection.deleteOne(ret);
console.dir(deleteResult.deletedCount);
// 删除符合条件的多个文档
const doc = { pageViews: { $gt: 10, $lt: 32768 } }
const deleteManyResult = await collection.deleteMany(doc);
console.dir(deleteManyResult.deletedCount);修改文档
- 更新单个文档:
const filter = { "instock.qty": { $gt: 6 } }
// update the value of the 'z' field to 42
const updateDocument = {
$set: { z: 42 }
}
// 更新多个
const result = await collection.updateOne(filter, updateDocument);
// 更新多个
const result = await collection.updateMany(filter, updateDocument);- 替换文档:
import { ObjectId } from 'mongodb'
const filter = { _id: new ObjectId('6656db02ad94f607a50a192e') }
// replace the matched document with the replacement document
const replacementDocument = {
z: 42
}
const result = await collection.replaceOne(filter, replacementDocument)