React 进阶指南

本文主要梳理React的知识链路以及底层运行逻辑
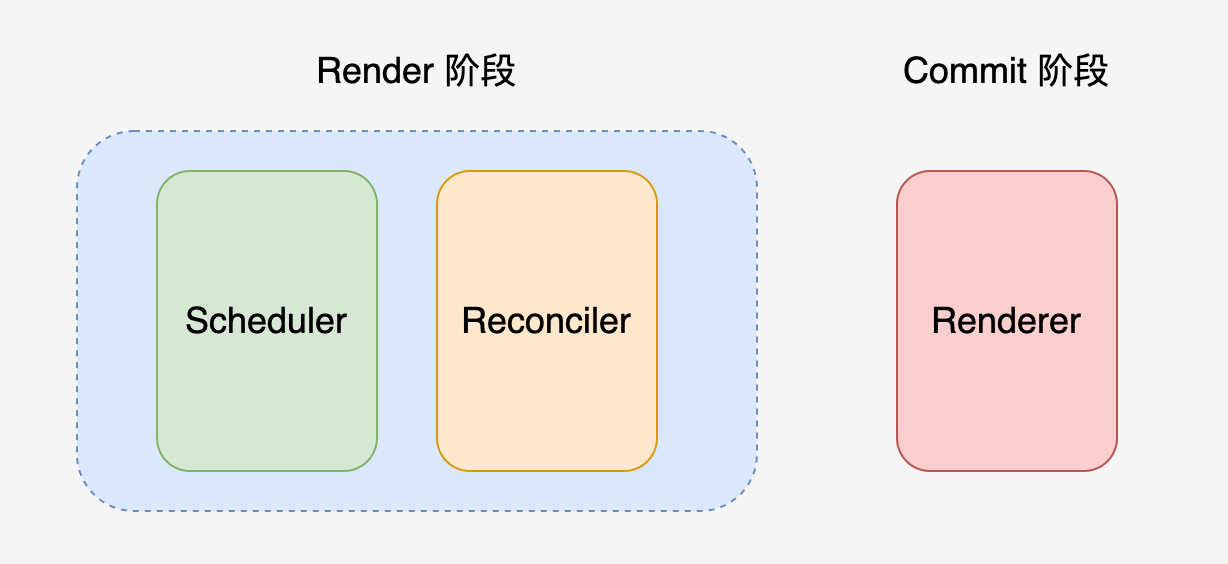
整体架构
React16以后采用了新的DOM比对算法Fiber, 相较于老架构Stack在进行虚拟DOM树比较的时候, 采用的是递归, 递归无法被中断, 计算会消耗大量的时间
Stack架构组成
组成
- Reconciler(协调器):VDOM 的实现,负责根据自变量变化计算出 UI 变化
- Renderer(渲染器):负责将 UI 变化渲染到宿主环境中
在 Reconciler 中,首次挂载组件会调用 mountComponent,更新的组件会调用 updateComponent,这两个方法都会递归更新子组件,更新流程一旦开始,中途无法中断。随着应用规模的增大, 这种架构也显露出对应的弊端
- CPU瓶颈 通过DIFF比对VDOM, 采用的递归算法, JS执行任务重耗时长, JS又是单线程执行, 无法同时执行其他任务, 从而导致丢帧卡顿
- IO瓶颈 由于更新任务没有优先级控制, 因此更新过程中无法及时中断后处理高优先级的任务, 因此导致响应延迟卡顿
Fiber架构组成
在React16开始, 架构中增加了调度器Scheduler, 用于进行优先级的控制。Scheduler 调度器,用来调度任务的优先级,从而解决 I/O 的瓶颈问题
而Reconciler 中的更新流程从递归变为了“可中断的循环过程”。每次循环都会调用 shouldYield 判断当前的 TimeSlice 是否有剩余时间,没有剩余时间则暂停更新流程,将主线程还给渲染流水线,等待下一个宏任务再继续执行。这样就解决了 CPU 的瓶颈问题
组成
- Scheduler(调度器) 调度任务的优先级, 高优先级的任务优先进入到
Reconciler - Reconciler(协调器)生成
Fiber对象, 收集副作用, 找出发生变化的节点, 打上不同的flags, 该过程从之前的递归变为了可中断的循环过程 - Renderer(渲染器) 根据协调器计算出来的虚拟DOM同步的渲染节点到视图上
渲染流程
React 中渲染流程分为两大阶段
- Render 阶段(异步可中断): 调合虚拟 DOM,计算出最终要渲染出来的虚拟 DOM
- Commit 阶段(同步不可断): 根据上一步计算出来的虚拟 DOM,渲染具体的 UI
Render阶段的工作是在内存中进行的, 不会更新宿主环境的UI, 因此这个阶段即使工作流程反复被中断, 也不会影响页面UI的展示
当 Scheduler 调度完成后,将任务交给 Reconciler,Reconciler 就需要计算出新的 UI,最后就由 Renderer 同步的进行渲染更新操作
Render阶段随时可以被中断, 中断条件如下
- 有其他更高优先级的任务需要执行
- 当前的
time slice没有剩余时间 - 发生其他错误
调度器
在 React v16 版本之前,采用的是 Stack 架构,所有任务只能同步进行,无法被打断,这就导致浏览器可能会出现丢帧的现象,表现出卡顿。React为了解决这个问题,从 v16 版本开始从架构上面进行了两大更新:
- 引入
Fiber - 新增了
Scheduler
Scheduler 在浏览器的原生 API 中实际上是有类似的实现的,这个 API 就是 requestIdleCallback。虽然浏览器有类似的 API,但是 React 团队并没有使用该 API,因为该 API 存在兼容性问题。因此 React 团队自己实现了一套这样的机制,这个就是调度器 Scheduler
RequestIdleCallback的执行时长
- 程序栈不为空
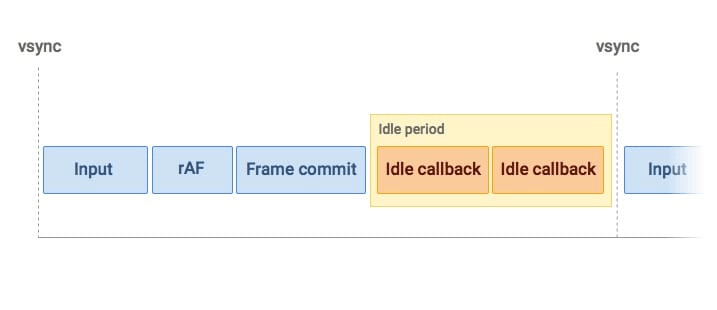
如果某一帧里面要执行的任务不多,在不到16ms的时间内就完成了任务的话,那么这一帧就会有一定的空闲时间,这段时间就恰好可以用来执行requestIdleCallback的回调
- 程序栈为空
当程序栈为空页面无需更新的时候,浏览器其实处于空闲状态,这时候留给requestIdleCallback执行的时间就可以适当拉长,最长可达到50ms,以防出现不可预测的任务(用户输入)来临时无法及时响应可能会引起用户感知到的延迟
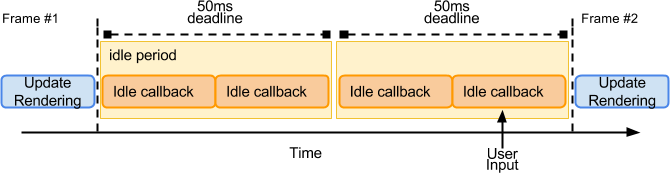
为什么是50ms?
用户操作之后,100ms以内的响应给用户的感觉都是瞬间发生,也就是说不会感受到延迟感,因此将空闲时间设置为 50ms,浏览器依然还剩下 50ms 可以处理用户的操作响应,不会让用户感到延迟
协调器
协调器是 render 阶段的第二阶段工作,类组件或者函数组件本身就是在这个阶段被调用的。
根据 Scheduler 调度结果的不同,协调器起点可能是不同的
- performSyncWorkOnRoot(同步更新流程)
- performConcurrentWorkOnRoot(并发更新流程)
// performSyncWorkOnRoot 会执行该方法
function workLoopSync(){
while(workInProgress !== null){
performUnitOfWork(workInProgress)
}
}// performConcurrentWorkOnRoot 会执行该方法
function workLoopConcurrent(){
while(workInProgress !== null && !shouldYield()){
performUnitOfWork(workInProgress)
}
}新的架构使用 Fiber(对象)来描述 DOM 结构,最终需要形成一颗 Fiber tree,这不过这棵树是通过链表的形式串联在一起的。
workInProgress 代表的是当前的 FiberNode。
performUnitOfWork 方法会创建下一个 FiberNode,并且还会将已创建的 FiberNode 连接起来(child、return、sibling),从而形成一个链表结构的 Fiber tree。
如果 workInProgress 为 null,说明已经没有下一个 FiberNode,也就是说明整颗 Fiber tree 树已经构建完毕。
上面两个方法唯一的区别就是是否调用了 shouldYield方法,该方法表明了是否可以中断。 performUnitOfWork在创建下一个 FiberNode 的时候,整体上的工作流程可以分为两大块:
- 递阶段
- 归阶段
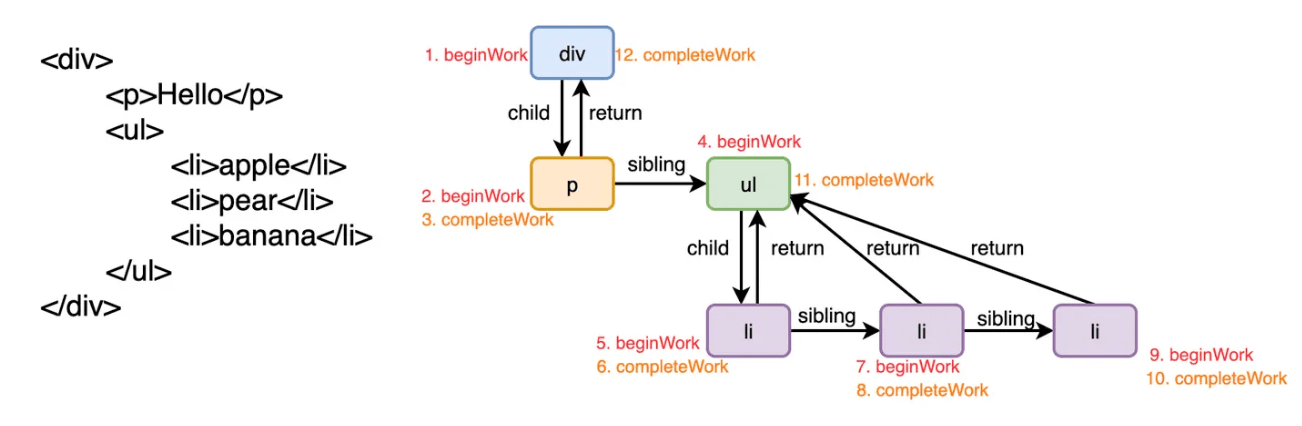
递阶段
递阶段会从 HostRootFiber 开始向下以深度优先的原则进行遍历,遍历到的每一个 FiberNode 执行 beginWork 方法。该方法会根据传入的 FiberNode 创建下一级的 FiberNode,此时可能存在两种情况:
- 下一级只有一个元素,
beginWork方法会创建对应的FiberNode,并于workInProgress连接
<ul>
<li></li>
</ul>这里就会创建 li 对应的 FiberNode,做出如下的连接:
LiFiber.return = UlFiber;- 下一级有多个元素,这是
beginWork方法会依次创建所有的子FiberNode并且通过sibling连接到一起,每个子FiberNode也会和workInProgress连接
<ul>
<li></li>
<li></li>
<li></li>
</ul>此时会创建 3 个 li 对应的 FiberNode,连接情况如下:
// 所有的子 Fiber 依次连接
Li0Fiber.sibling = Li1Fiber;
Li1Fiber.sibling = Li2Fiber;
// 子 Fiber 还需要和父 Fiber 连接
Li0Fiber.return = UlFiber;
Li1Fiber.return = UlFiber;
Li2Fiber.return = UlFiber;由于采用的是深度优先的原则,因此无法再往下走的时候,会进入到归阶段。
归阶段
归阶段会调用 completeWork 方法来处理 FiberNode,做一些副作用的收集。
当某个 FiberNode 执行完了 completeWork 方法后,如果存在兄弟元素,就会进入到兄弟元素的递阶段,如果不存在兄弟元素,就会进入父 FiberNode 的归阶段
function performUnitOfWork(fiberNode){
// 省略 beginWork
if(fiberNode.child){
performUnitOfWork(fiberNode.child);
}
// 省略 CompleteWork
if(fiberNode.sibling){
performUnitOfWork(fiberNode.sibling);
}
}最后我们来看一张图:
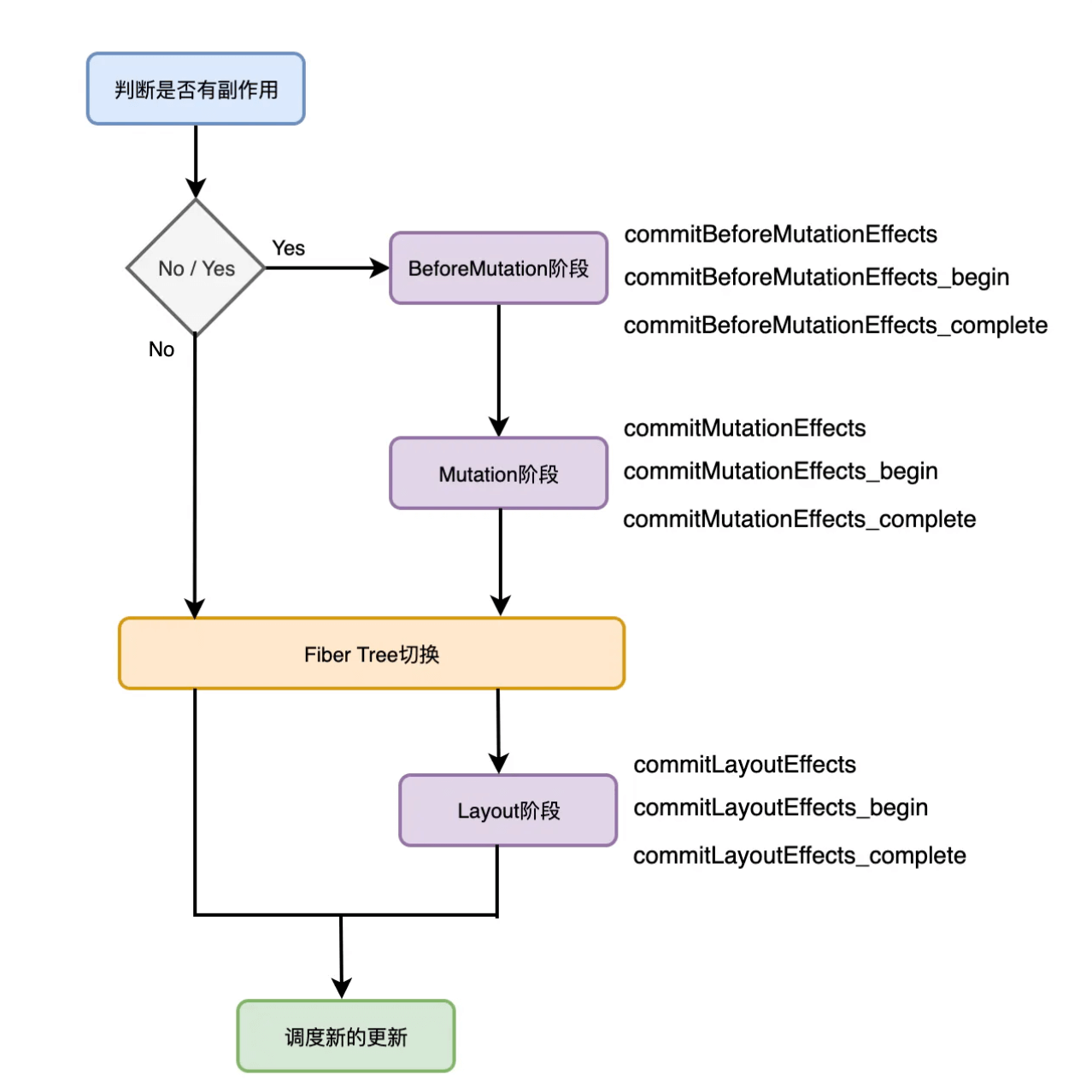
渲染器
Renderer 工作的阶段被称之为 commit 阶段。该阶段会将各种副作用 commit 到宿主环境的 UI 中。
相较于之前的 render 阶段可以被打断,commit 阶段一旦开始就会同步执行直到完成渲染工作。
整个渲染器渲染过程中可以分为三个子阶段:
- BeforeMutation 阶段
- Mutation 阶段
- Layout 阶段
Fiber
作用
在以前的数据结构React Element中, React Element如果作为核心模块操作的数据结构:
存在的问题如下
- 无法表达节点之间的关系
- 字段有限, 不好拓展(无法表达状态)
因此, 需要一个新的数据结构来解决这个问题, 这个数据结构就是FiberNode
FiberNode
- 介于
React Element与真实UI节点之间 - 能够表达节点之间的关系
- 方便拓展(不仅作为数据存储单元, 也能作为工作单元)
在React中就存在以下节点类型:
- JSX
- React Element
- FiberNode
- DOM Element
实现思路
为了实现任务的中断, 将DOM比对的算法拆分成了两部分, 第一部分是虚拟DOM的比对(这个过程可以中断), 第二部分是真实DOM对象的更新(无法中断)。
整体思路如下
Babel将JSX转化为React.createElement的调用,React.createElement调用后返回虚拟DOM(下文都统称VDOM)对象- 构建
Fiber对象,采用循环的方式从VDOM对象中找到每一个内部的VDOM对象,为每一个VDOM对象构建Fiber对象(JS对象), 它是从VDOM对象演化而来。它有更多的属性来描述节点关系的信息, 其中有一个核心属性effectTag表明Fiber要执行的操作, 构建完成的Fiber对象存储在一个数组中 - 循环
Fiber数组, 根据Fiber对象中存储的当前节点要操作的类型, 最后应用在真实的DOM中
在初始渲染和更新的两个流程中可以抽象为:
- DOM初始渲染: VDOM -> Fiber -> Fiber数组 -> DOM
- DOM更新操作: 新旧Fiber对比 -> Fiber数组 -> DOM
Fiber的核心属性
{
type // 节点类型(元素 | 文本 | 组件)
props // 节点属性
stateNode // 节点真实DOM对象 | 组件实例对象
tag // 节点标记(具体类型的分类 hostRoot | hostComponent | classComponent | functionComponent)
effects // 数组, 存储需要更改的 Fiber 对象
effectTag // 字符串, 当前 Fiber 要被执行的操作(新增,删除,修改)
parent // 当前 Fiber 的父级 Fiber
child // 当前 Fiber 的子级 Fiber
sibling // 当前 Fiber 的下一个兄弟 Fiber
alternate // Fiber 备份( Fiber 比对时使用 )
}Reconciler
Reconciler 是 React 中的协调器,它的主要工作是协调 Fiber 对象,通过DIFF找出发生变化的节点,打上不同的 flags,并且收集副作用。
工作方式
对于同一个节点,比较其ReactElement与FiberNode,生成子FiberNode。并根据比较的结果生成不同的标记(插入、移动、删除...),对应不同宿主环境API的执行。
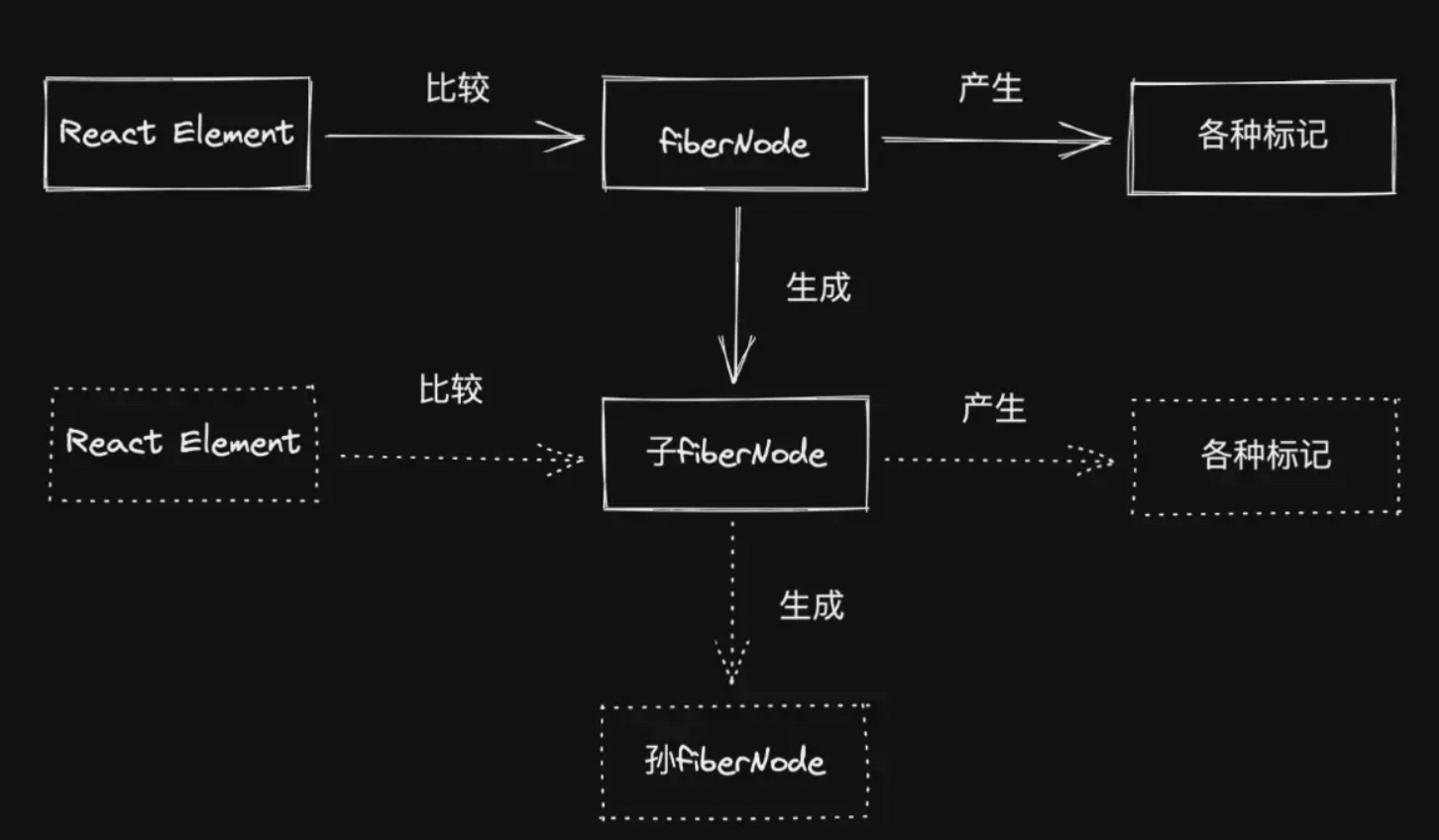
当所有ReactElement比较完成后, 会生成一颗fiberNode树, 一共会存在两颗fiberNode树
- current: 与视图中真实UI对应的
fiberNode树 - workInProgress: 触发更新后, 正在
reconciler中计算的fiberNode树
节点处理顺序
JSX节点的处理过程是通过以DFS(深度优先遍历)的顺序遍历ReactElement。
遍历过程
该遍历过程通过递归完成,又将阶段分为了递和归的两个阶段:
- 递: 如果有子节点,遍历子节点, 对应
beginWork函数 - 归: 没有子节点,遍历兄弟节点, 对应
completeWork函数
// React节点遍历过程主体代码
function workLoop() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
function performUnitOfWork(fiber: FiberNode) {
//beginWork每次返回子节点
const next = beginWork(fiber);
if (next === null) {
completeUnitOfWork(fiber);
} else {
workInProgress = next;
}
}
function completeUnitOfWork(fiber: FiberNode) {
let node: FiberNode | null = fiber;
do {
const next = completeWork(node);
if (next !== null) {
workInProgress = next;
return;
}
const sibling = node.sibling;
if (sibling) {
workInProgress = next;
return;
}
node = node.return;
workInProgress = node;
} while (node !== null);
}节点的分类
FiberNode中的tag属性用来标记节点的类型,主要分为以下几种:
HostRoot:根DOM节点对应的类型(一般为div#app)ClassComponent:类组件FunctionComponent:函数组件HostComponent:原生DOM节点HostText:文本节点
触发更新模块
常见的触发更新的方式有以下几个:
ReactDOM.createRoot().render(或者旧版本ReactDOM.render)
this.setState(Class组件)
useState的dispatch方法
第一条是根组件导致的更新, 后面的两条更新可能发生于任意组件,更新的流程是从根节点开始递归的
因此我们需要从触发更新的节点向上遍历到根节点, 还需要一个统一的根节点保存通用信息
更新机制组成
React的更新机制必须同时兼容上述的集中更新方式, 还需要能够进行后续的拓展(同步更新到并发更新), 因此设计了两种数据结构来存储信息
- 代表更新的数据结构(Update)
- 消费update的数据结构(UpdateQueue)

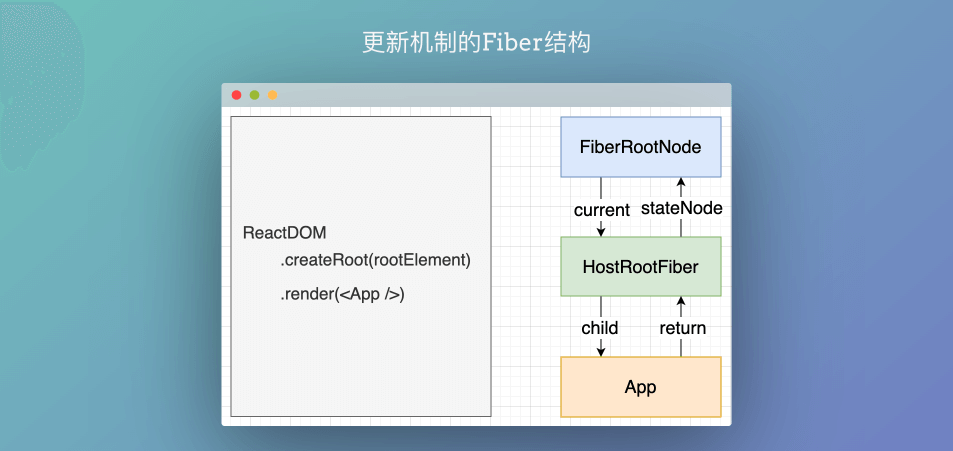
建立统一根节点
因为更新可能发生于任意组件, 而更新流程是从根节点递归的
因此, 还需要建立统一的根节点FiberRootNode来保存通用信息, 源码中通过调用ReactDOM.createRoot()创建根节点FiberRootNode。其中传入的rootElement也有对应的FiberNode - HostRootFiber
首屏渲染
更新流程的目的:
- 生成
wip(workInProgress) fiberNode树 - 标记副作用
flags
更新流程的步骤, 是通过上文提到的递和归的过程
BeginWork内部处理
INFO
HostRoot的beginWork工作流程:
- 计算状态的最新值
- 创建fiberNode
HostComponent的beginWork工作流程:
- 只有创建子fiberNode
HostText没有beginWork工作流程(因为他没有子节点)
CompleteWork内部处理
内部流程
- 对于Host类型FiberNode, 构建离屏DOM树
- 标记Update Flag
性能优化策略
flags 分布在不同的fiberNode中, 如何快速找到?
- 利用completeWork向上遍历(归)的流程, 将子FiberNode的flags冒泡到父fiberNode